Sollten die Grafiken nicht funktionieren, kannst du die SVG-freie Version dieser Seite auswählen.
Die Grafiken sind derzeit nicht im SVG-Format. (zur SVG-Version)
Diese Seite ist eine kurze grafische Referenz der am häufigsten verwendeten Git-Kommandos. Wenn du schon einige Git-Grundlagen kennst, kannst du mit dieser Seite dein Verständnis vertiefen. Wenn du an der Erstellung dieser Seite interessiert bist, sieh dir mein GitHub-Repository dazu an.
Ebenfalls empfohlen: Visualizing Git Concepts with D3 (englisch).
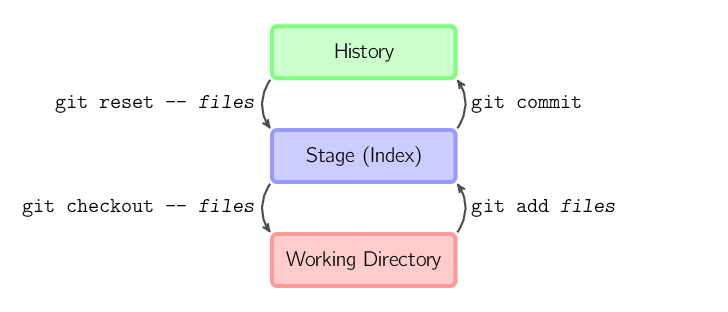
Die vier oben in der Grafik erwähnten Kommandos kopieren Dateien zwischen dem Arbeitsverzeichnis, dem Index (stage) und dem Projektarchiv (history).
git add Dateien
kopiert die Dateien aus dem Arbeitsverzeichnis in ihrem
aktuellen Zustand in den Index.
git commit
speichert einen Schnappschuss des Indexes als Commit im Projektarchiv.
git reset -- Dateien
entfernt geänderte Dateien aus dem Index; dazu werden die Dateien
des letzten Commits in den Index kopiert. Damit kannst du ein git
add Dateien rückgängig machen. Mit git reset
kannst du alle geänderten Dateien aus dem Index entfernen.
git checkout -- Dateien
kopiert Dateien aus dem Index in das Arbeitsverzeichnis. Damit
kannst du die Änderungen im Arbeitsverzeichnis verwerfen.
Du kannst mit git reset -p, git checkout -p oder
git add -p interaktiv entscheiden, welche Blöcke (hunks) von
Änderungen (in allen oder den angegebenen Dateien) verwendet werden
sollen.
Es ist auch möglich, den Index zu überspringen und Dateien direkt aus dem Archiv (history) auszuchecken oder Änderungen im Arbeitsverzeichnis direkt zu committen:
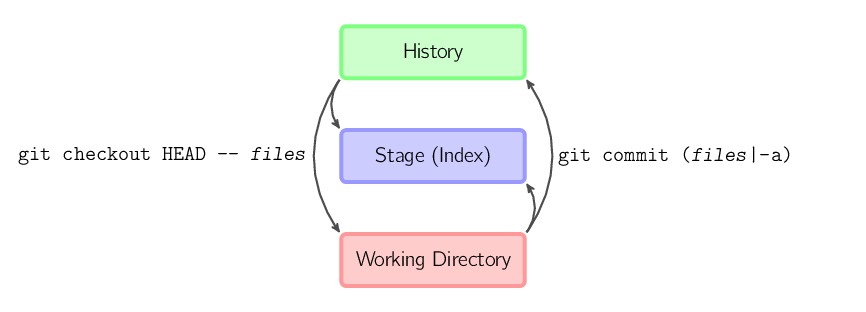
git commit -a
ist gleichbedeutend mit git add auf allen im letzten Commit
bekannten Dateien, gefolgt von einem git commit.
git commit Dateien
erzeugt einen neuen Commit mit dem Inhalt aller aufgeführten
Dateien aus dem Arbeitsverzeichnis. Zusätzlich werden die
Dateien in den Index kopiert.
git checkout HEAD -- Dateien
kopiert die Dateien vom letzten Commit sowohl in den Index als
auch in das Arbeitsverzeichnis.
Im weiteren Verlauf werden zur Darstellung Graphen der folgenden Art verwendet.
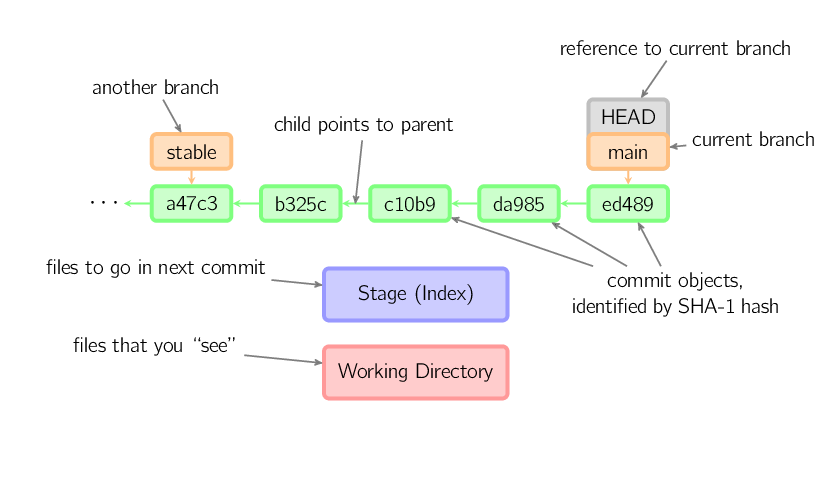
Commits werden in grün mit ihren Fünf-Zeichen-IDs dargestellt, sie verweisen auf ihre Eltern-Commits (parents). Branches werden in orange dargestellt, sie zeigen auf einen bestimmten Commit. Der aktuelle Branch wird mit der speziellen Referenz HEAD identifiziert. In diesem Bild sieht man die fünf letzten Commits, wobei ed489 der jüngste ist. main ("current branch", der aktuelle Branch) zeigt auf genau diesen Commit, wohingegen stable ("another branch", ein anderer Branch) auf einen der Vorfahren von main verweist.
(Zu allen Kommandos sind zum besseren Verständnis deutsche Übersetzungen angegeben. Da es sich dabei jedoch um Kommandos handelt, die nur im englischsprachigen Original zur Verfügung stehen, werden auch in den Erklärungen weitestgehend die Originalbegriffe verwendet.)
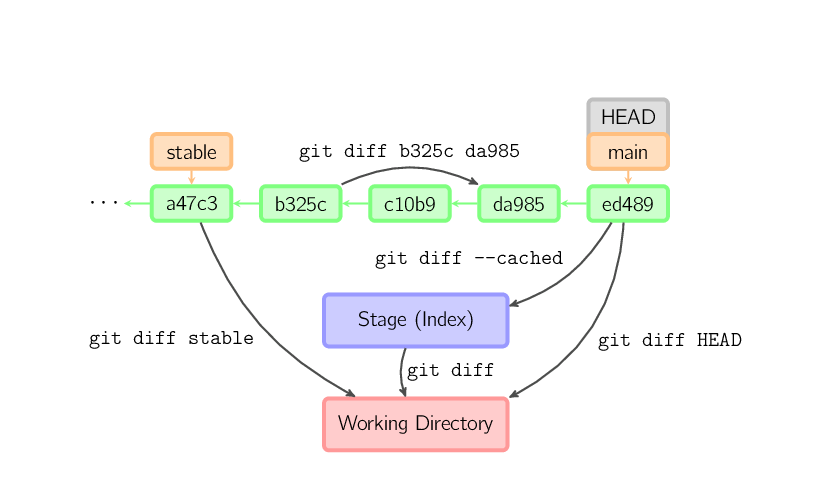
Es gibt verschiedene Möglichkeiten, die Unterschiede zwischen Commits anzuzeigen. Nachfolgend ein paar Beispiele. An jedes dieser Kommandos können ein oder mehrere Dateinamen als Argument angehängt werden, um die Darstellung auf diese Dateien einzuschränken.
Mit dem commit-Kommando erzeugt git ein neues Commit-Objekt
mit den Dateien aus dem Index. Als Vorgänger wird der aktuelle Commit
verwendet. Zusätzlich wird der aktuelle Branch auf den neuen Commit
verschoben. Im folgenden Bild ist der aktuelle Branch main. Vor der
Ausführung des Kommandos zeigte main auf ed489. Durch das
Kommando wird ein neuer Commit f0cec mit dem Vorläufer ed489
erstellt und der Branch main auf den neuen Commit verschoben.
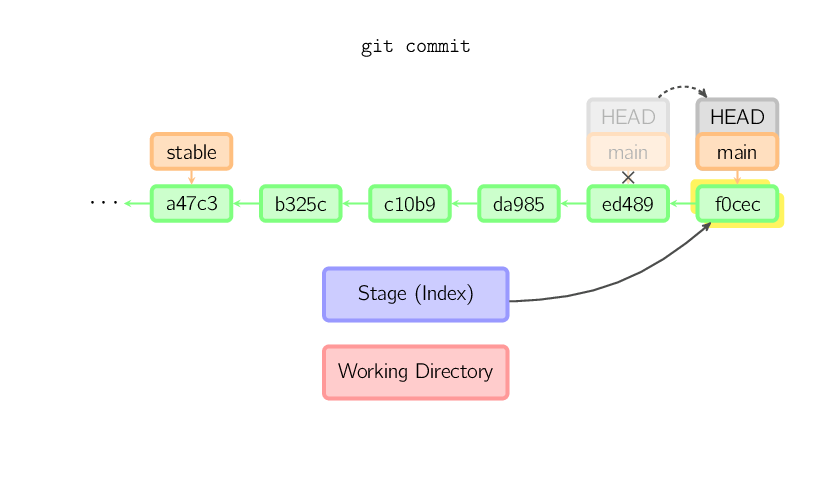
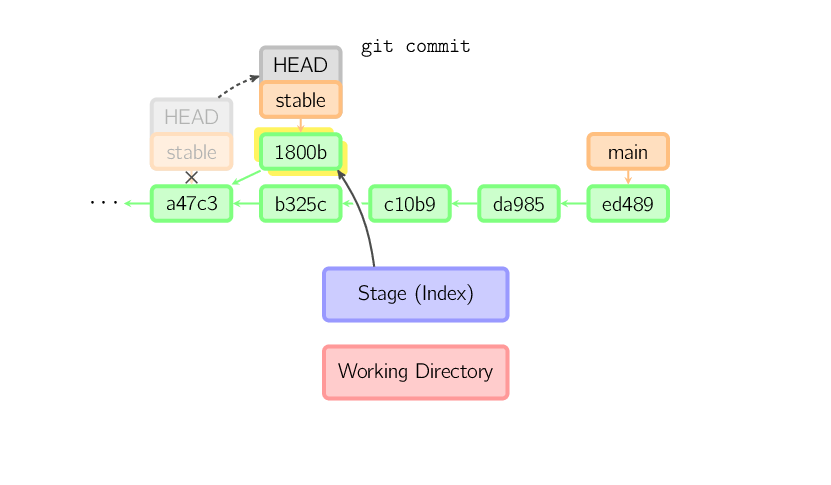
Das gleiche geschieht auch, wenn der aktuelle Branch ein Vorgänger eines anderen ist. Im nachfolgenden Bild wird ein Commit auf dem Branch stable ausgeführt, der ein Vorgänger von main ist, was einen Commit 1800b erzeugt. Danach ist stable kein Vorgänger von main mehr. Um die beiden Branches wieder zusammenzuführen, ist ein merge oder rebase nötig.
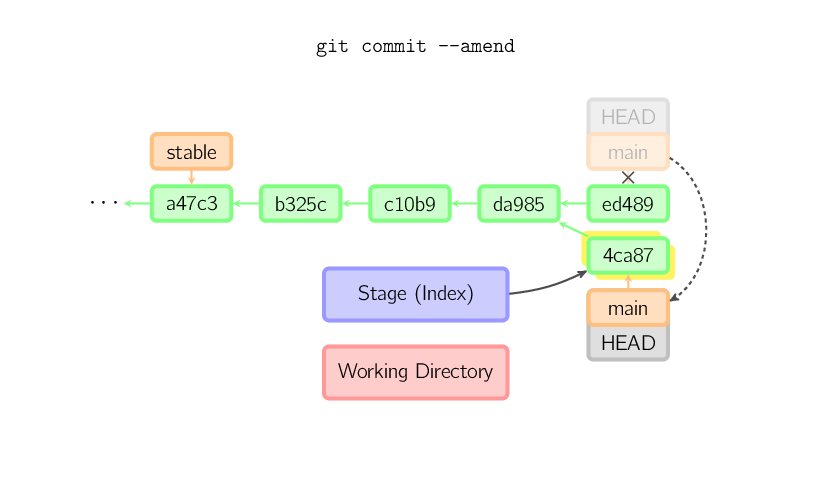
Einen Fehler in einem Commit kannst Du mit git commit --amend
korrigieren. Mit diesem Befehl erstellt git einen neuen Commit mit dem selben
Vorgänger. Der ursprüngliche Commit wird irgendwann verworfen wenn nichts
mehr auf ihn verweist.
Ein vierter Fall, ein Commit mit detached HEAD, wird weiter unten ausführlich erklärt.
Mit dem checkout-Kommando werden Dateien aus dem Projektarchiv
oder dem Index in das Arbeitsverzeichnis kopiert. Optional wird damit auch der
Branch gewechselt.
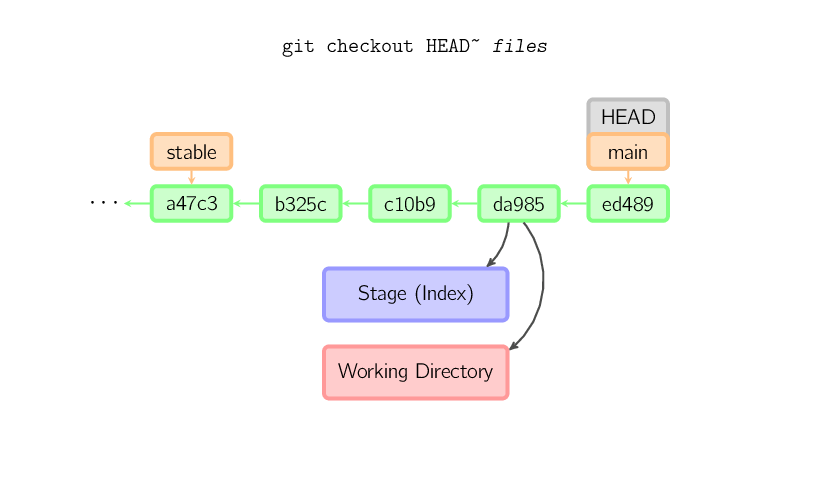
Wird ein Dateiname (und/oder -p) angegeben, so kopiert git
diese Dateien aus dem gegebenen Commit in den Index und das
Arbeitsverzeichnis. Zum Beispiel kopiert git checkout HEAD~ foo.c
die Datei foo.c aus dem Commit mit dem Namen HEAD~ (der
Vorgänger des aktuellen Commits) sowohl in das Arbeitsverzeichnis als auch in
den Index. Wird kein Commit-Name angegeben, so werden die Dateien aus dem
Index kopiert. Beachte: Der aktuelle Branch ändert sich nicht.
Wenn beim Checkout kein Dateiname sondern der Name eines (lokalen) Branches angegeben wird, so wird die Referenz HEAD auf diesen Branch verschoben, du "wechselst" also zu dem angegebenen Branch. Daraufhin werden die Dateien im Index und im Arbeitsverzeichnis denen aus dem Commit angepasst. Jede Datei, die im neuen Commit (a47c3 s.u.) existiert, wird kopiert; Jede Datei, die im alten Commit (ed489) existiert, aber nicht im neuen, wird gelöscht. Alle weiteren Dateien werden ignoriert.
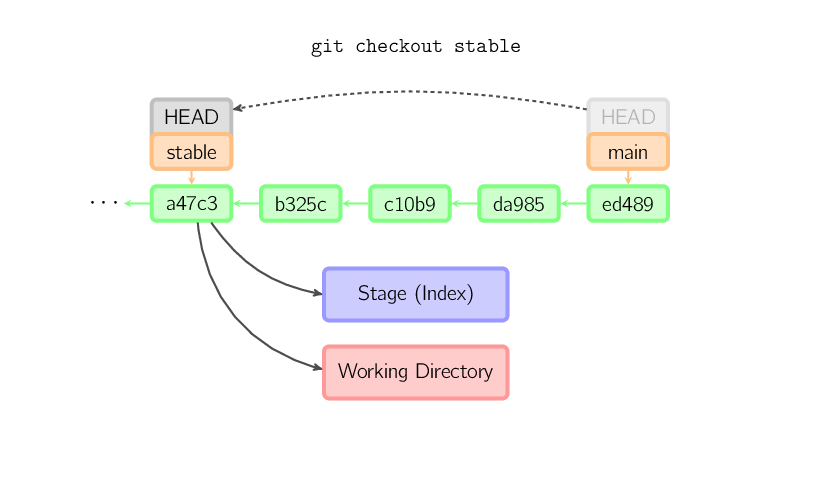
Wenn kein Dateiname angegeben wird und die angegebene Referenz
kein (lokaler) Branch ist (also z.B. ein Tag, ein Remote-Branch, eine
SHA-1-ID oder etwas wie main~3), erhalten wir einen anonymen
Branch, genannt detached HEAD. Das bietet sich besonders an, um in
der Versionsgeschichte herumzuspringen. Sagen wir mal, du willst die Version
1.6.6.1 von git kompilieren. Dann kannst du einfach mit dem Befehl git
checkout v1.6.6.1 (welches ein Tag und kein Branch ist) den Quellcode
von diesem Zeitpunkt auschecken und damit arbeiten. Später kannst Du zu einem
anderen Branch zurückspringen, z. B. mit git checkout main. Ein
Commit mit einem detached HEAD verhält sich jedoch etwas anders als
wir es gewohnt sind. Dieser Fall wird unten
behandelt.
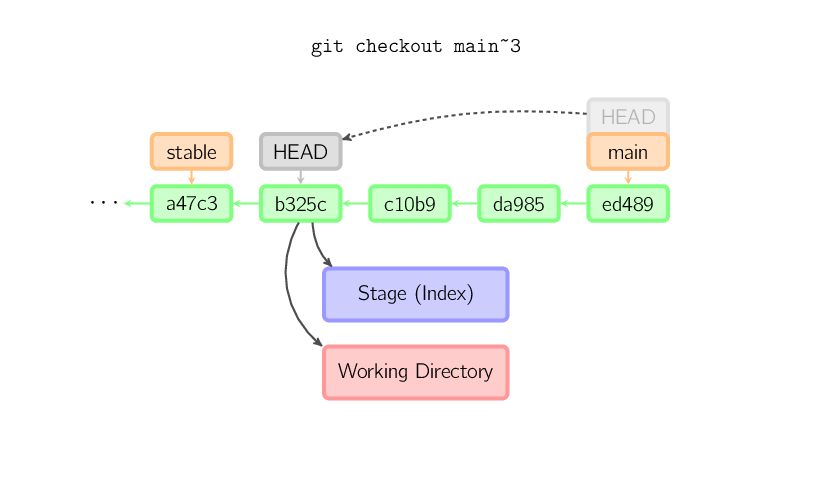
Ist die Referenz HEAD detached (losgelöst), so funktionieren Commits beinahe wie gehabt, es wird nur kein benannter Branch aktualisiert. Dies kannst du dir als anonymen Branch vorstellen.
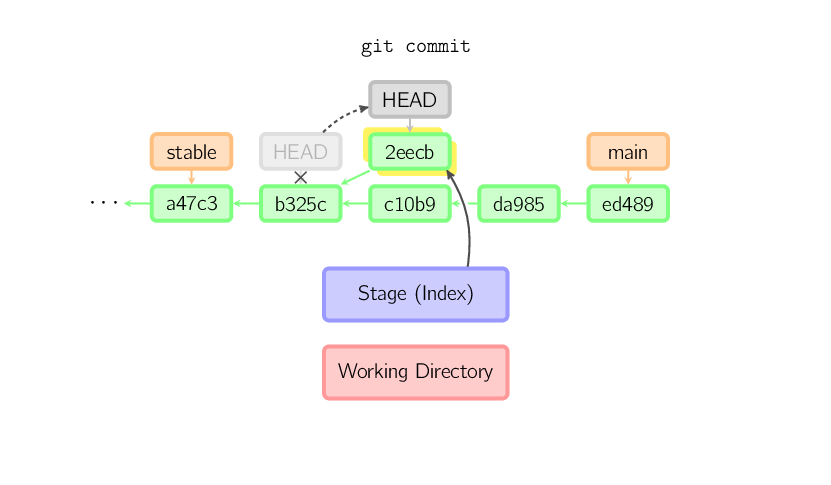
Sobald du etwas anderes auscheckst, etwa den Branch main, wird
der Commit (vermutlich) von nichts mehr referenziert und geht verloren. In der
Grafik gibt es nach dem git checkout main nichts mehr, das auf
den Commit 2eecb zeigt.
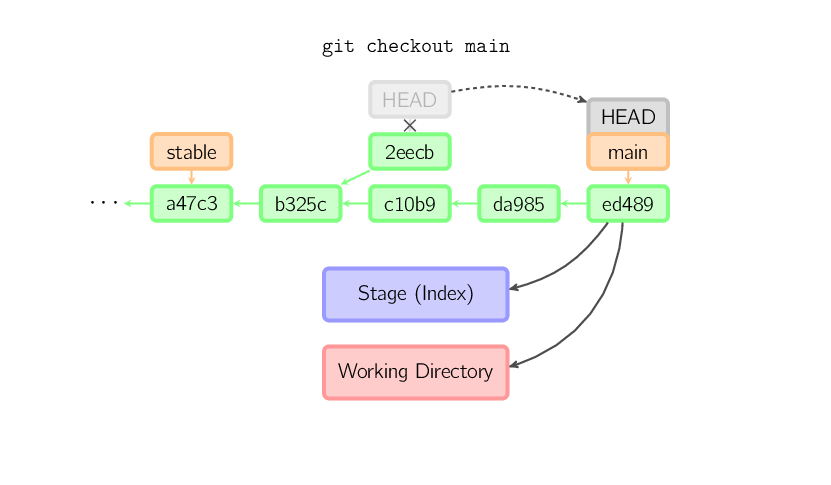
Wenn du aber diesen Zustand speichern möchtest, kannst du einen neuen
benannten Branch mit git checkout -b name erstellen.
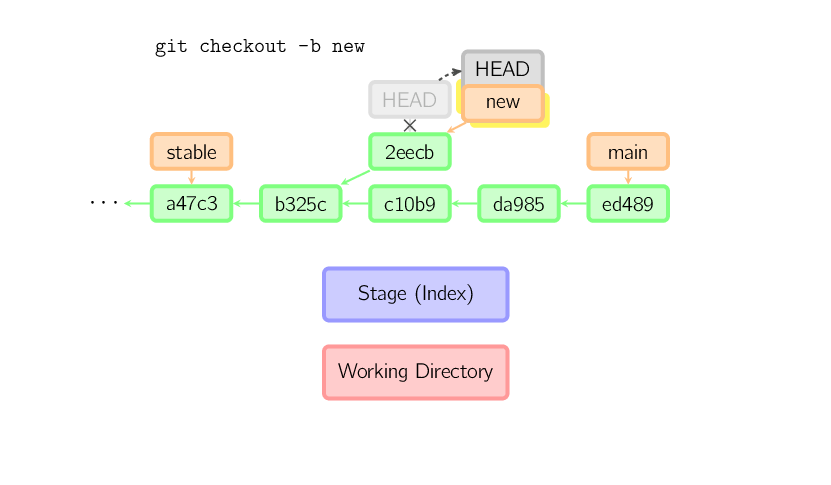
Das reset-Kommando verschiebt den aktuellen Branch an eine
andere Position. Optional aktualisiert es den Index und das
Arbeitsverzeichnis. Er wird auch dazu benutzt, Dateien aus dem Projektarchiv
in den Index zu kopieren ohne das Arbeitsverzeichnis zu verändern.
Wird ein Commit ohne Dateinamen angegeben, so wird der aktuelle Branch auf
diesen Commit gesetzt und der Index mit dessen Inhalt überschrieben. Wird
--hard benutzt, so wird auch das Arbeitsverzeichnis aktualisiert.
Mit --soft wird weder der Index noch das Arbeitsverzeichnis
verändert.
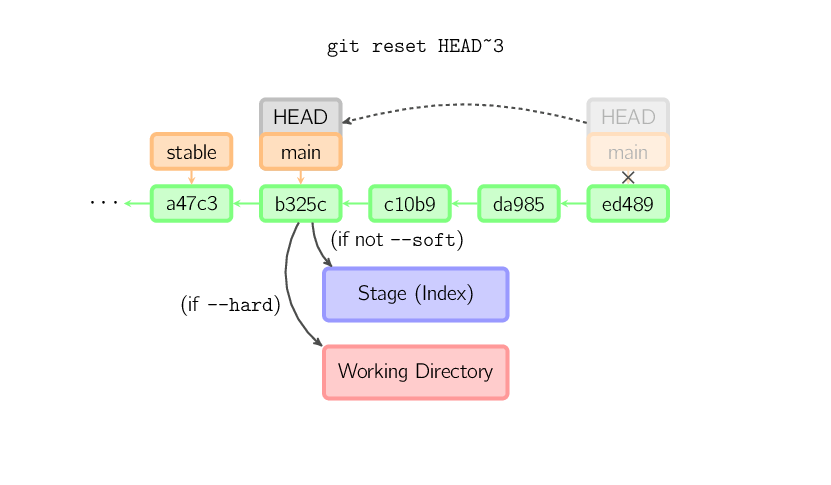
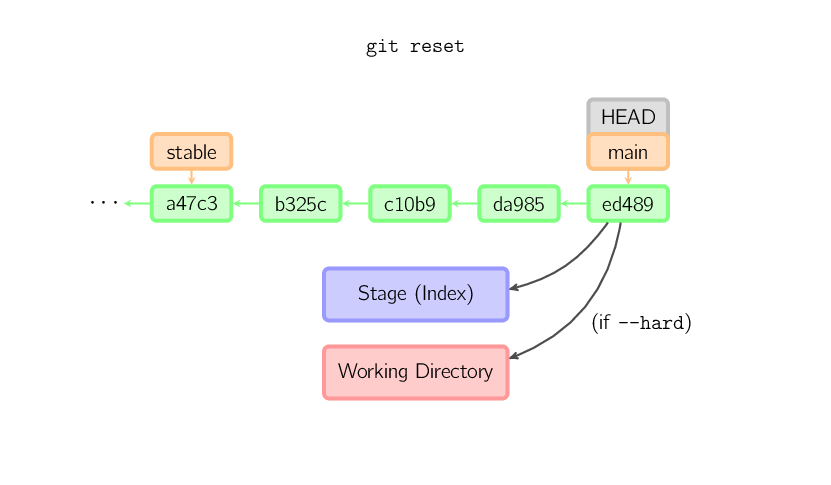
Wird kein Commit angegeben, so arbeitet reset mit
HEAD. In diesem Falle wird der Branch nicht verschoben. Stattdessen
wird der Index (und das Arbeitsverzeichnis mit --hard) mit dem
Inhalt des letzten Commits überschrieben.
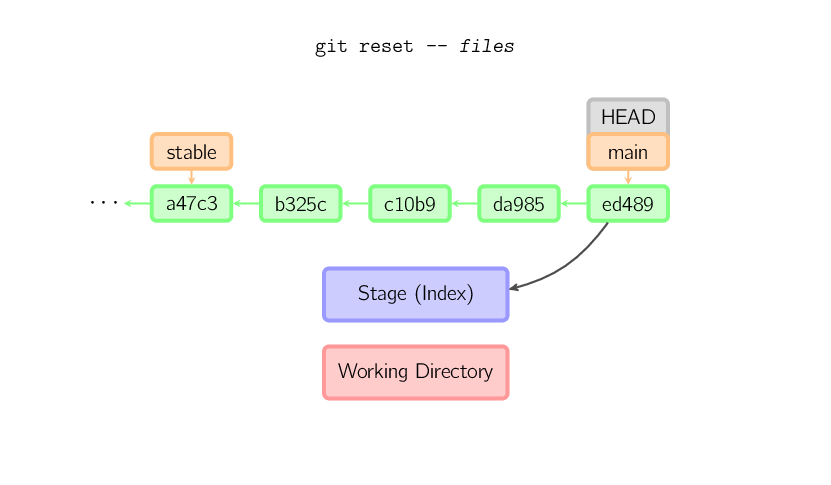
Wird ein Dateiname (und/oder die Option -p) angegeben, so
funktioniert das Kommando ähnlich wie ein checkout
mit einem Dateinamen, außer dass ausschließlich der Index (und nicht das
Arbeitsverzeichnis) aktualisiert wird. (Du kannst auch anstatt von
HEAD den Commit angeben, dessen Dateien verwendet werden sollen.)
Mit merge wird ein neuer Commit erstellt, der Änderungen
anderer Commits mit dem aktuellen zusammenführt. Vor dem merge
muss der Index dem aktuellen Commit entsprechen. Im einfachsten Fall ist der
andere Commit ein Vorgänger des aktuellen, dann muss gar nichts getan werden.
Im nächsteinfacheren Fall ist der aktuelle Commit ein Vorgänger des anderen
Commits. Dann erzeugt das Kommando einen sogenannten
fast-forward-Merge ("vorspulen"): Die aktuelle Referenz wird einfach
auf den anderen Commit verschoben, danach wird dieser "ausgecheckt" (wie in
checkout).
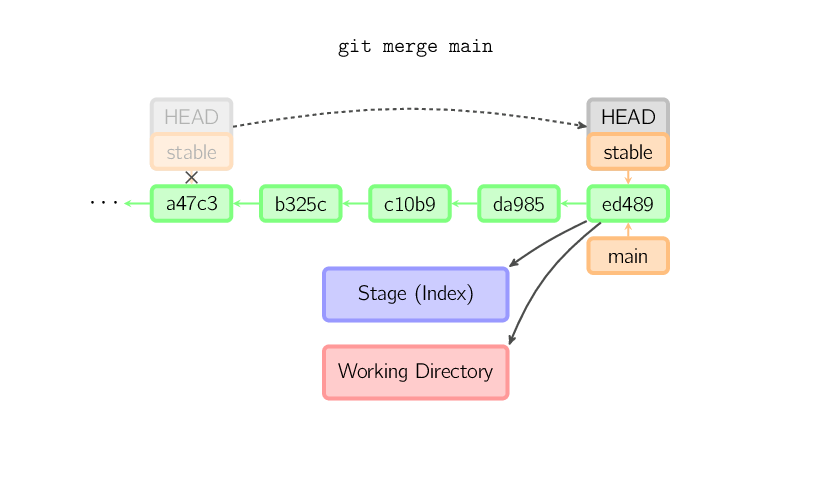
In den anderen Fällen muss ein "richtiger" Merge durchgeführt werden. Standardmäßig wird ein "rekursiver" Merge durchgeführt (du kannst aber auch andere Strategien angeben). Dieser nimmt den aktuellen Commit (unten ed489), den anderen Commit (33104) und ihren gemeinsamen Vorgänger (b325c) und führt einen Drei-Wege-Merge (Seite auf Englisch) durch. Das Ergebnis wird im Arbeitsverzeichnis und dem Index gespeichert. Dann wird ein Commit erzeugt, der zwei Eltern (33104 und ed489) hat.
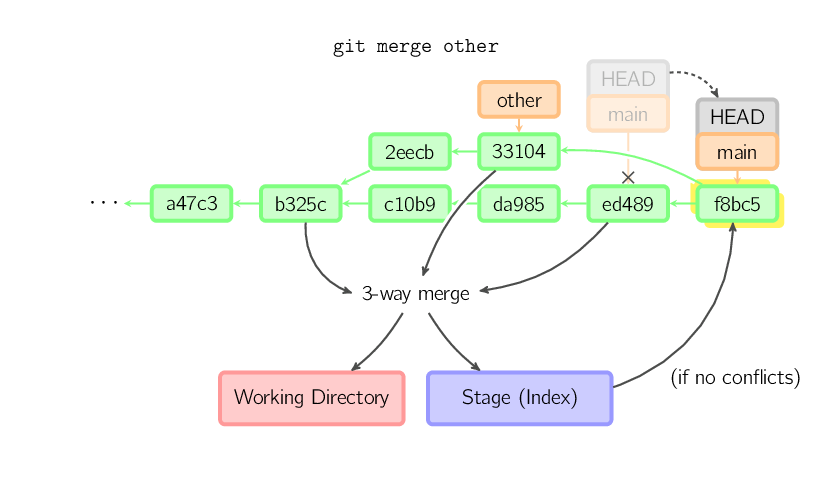
Das cherry-pick-Kommando "kopiert" einen Commit. Es erzeugt
einen neuen Commit auf dem aktuellen Branch mit der selben Bezeichnung und
der selben Änderung wie im angegebenen Commit.
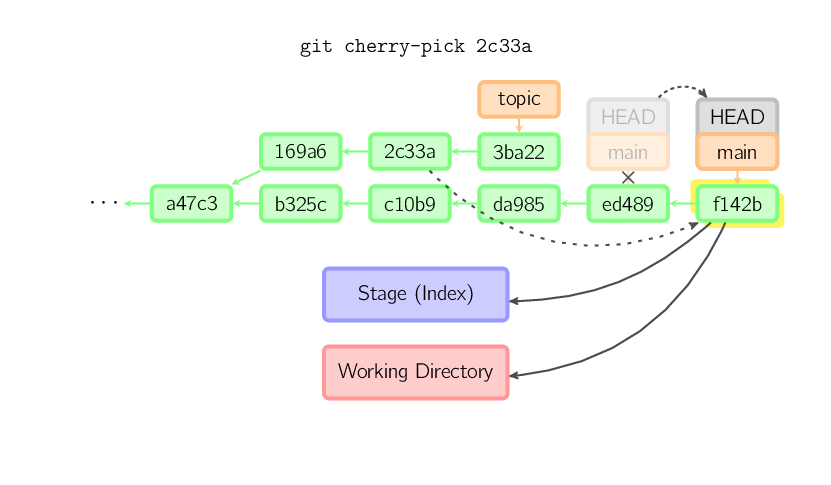
Ein Rebase ist eine Alternative zu einem Merge um mehrere Branches zusammenzuführen. Während ein Merge einen einzelnen neuen Commit mit zwei Eltern erzeugt und einen nicht-linearen Commit-Verlauf hinterlässt, spielt ein Rebase die Commits des aktuellen Branches auf das Ende des anderen Branch auf, wodurch der Commit-Verlauf linearisiert wird. Im Prinzip ist das ein automatisierter Weg, mehrere cherry-pick-Kommandos hintereinander auszuführen.
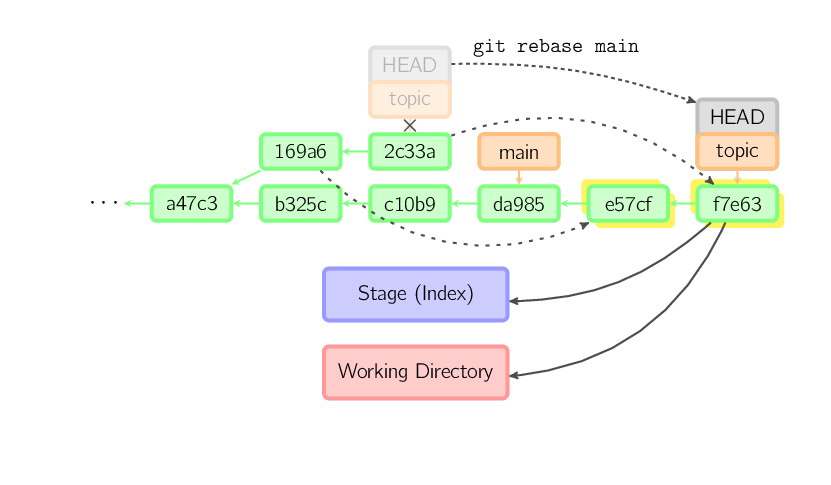
Der obige Befehl nimmt alle Commits, die im Branch topic, aber nicht im Branch main existieren (169a6 und 2c33a), spielt diese auf den Branch main auf und verschiebt dann den Branch sowie den HEAD auf den zuletzt angehängten Commit. Beachte, dass danach nichts mehr auf die alten Commits verweist und diese gegebenenfalls von der Garbage Collection gelöscht werden.
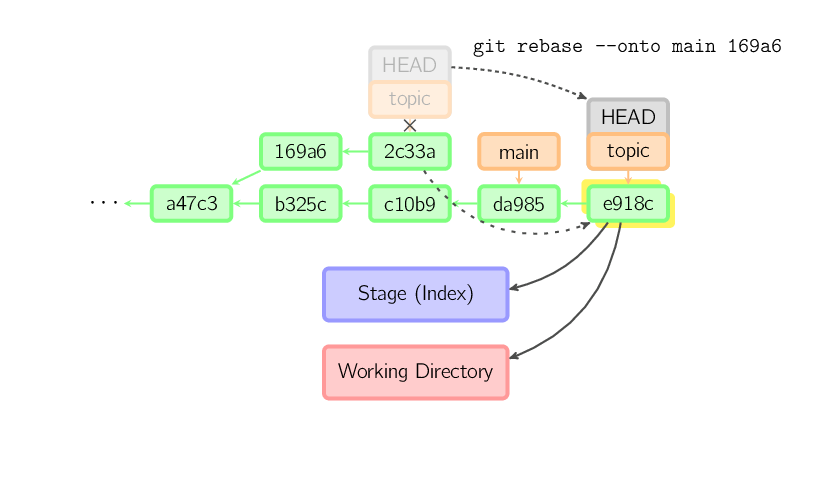
Mit der Option --onto läßt sich einschränken, wie weit
rebase beim Neuaufspielen zurückgehen soll. Das folgende Kommando
hängt an den main die letzten Commits aus dem aktuellen Branch
nach dem Commit 169a6 an (nur 2c33a).
Durch Verwendung von git rebase --interactive können
kompliziertere Aktionen mit den betroffenen Commits durchgeführt werden:
drop (Verwerfen), reorder (Ändern der Reihenfolge),
modify (Verändern eines Commits) und squash (Kombinieren
mehrerer Commits). Zu diesen Aktionen gibt es keine naheliegende
Visualisierung. Details können in der
Dokumentation zu git-rebase(1)
nachgelesen werden.
Der Inhalt von Dateien wird nicht wirklich im Index (.git/index) oder in Commit-Objekten gespeichert. Stattdessen wird jede Datei, identifiziert durch ihren SHA-1-Hash, in der Objektdatenbank (.git/objects) als blob gespeichert. Die Index-Datei enthält Dateinamen neben den Bezeichnern des assozierten Blobs sowie weitere Informationen. Für die Dateien von Commits existiert ein weiterer Datentyp, der tree (Baum), der ebenfalls durch seinen Hash identifiziert wird. Trees entsprechen Verzeichnissen im Arbeitsverzeichnis und enthalten, entsprechend ihres Inhalts von Dateien und weiteren Verzeichnissen, eine Liste von Blobs und Trees. Jeder Commit speichert den Bezeichner des zugehörigen "top-level"-Trees. Dieser Tree wiederum enthält alle Blobs und weitere Trees für Unterverzeichnisse, die zu diesem Commit gehören.
Führst du einen Comit mit einem detached HEAD durch, so wird der
letzte Commit doch noch von etwas referenziert: Dem reflog von
HEAD. Allerdings verfällt diese Referenz (je nach Konfiguration) nach
einer Weile, so dass der Commit, ähnlich wie die verwaisten Commits aus
git commit --amend oder git rebase, von der
Garbage Collection (Müllabfuhr) gelöscht wird.
Im Folgenden werden wir den Effekt einiger Kommandos Schritt für Schritt nachvollziehen, ähnlich wie in Visualizing Git Concepts with D3 (englisch).
Wir beginnen damit, ein Projektarchiv zu erstellen:
$ git init foo
$ cd foo
$ echo 1 > myfile
$ git add myfile
$ git commit -m "version 1"
Mit Hilfe der folgenden Funktionen können wir den aktuellen Zustand des Projektarchivs einsehen:
show_status() {
echo "HEAD: $(git cat-file -p HEAD:myfile)"
echo "Stage: $(git cat-file -p :myfile)"
echo "Worktree: $(cat myfile)"
}
initial_setup() {
echo 3 > myfile
git add myfile
echo 4 > myfile
show_status
}
Anfangs ist alles im Zustand "1".
$ show_status
HEAD: 1
Stage: 1
Worktree: 1
Hier können wir die Änderungen des Zustands von Index ("Stage") und Arbeitsverzeichnis ("Worktree") mit den Kommandos add und commit sehen.
$ echo 2 > myfile
$ show_status
HEAD: 1
Stage: 1
Worktree: 2
$ git add myfile
$ show_status
HEAD: 1
Stage: 2
Worktree: 2
$ git commit -m "version 2"
[main 4156116] version 2
1 file changed, 1 insertion(+), 1 deletion(-)
$ show_status
HEAD: 2
Stage: 2
Worktree: 2
Wechseln wir nun zu einem initialen Zustand, in dem alle drei Stufen verschieden sind.
$ initial_setup
HEAD: 2
Stage: 3
Worktree: 4
Entsprechend der Diagramme oben sehen wir hier die Veränderungen durch verschiedene Kommandos.
git reset -- myfile kopiert vom HEAD in den Index:
$ initial_setup
HEAD: 2
Stage: 3
Worktree: 4
$ git reset -- myfile
Unstaged changes after reset:
M myfile
$ show_status
HEAD: 2
Stage: 2
Worktree: 4
git checkout -- myfile kopiert vom Index ins
Arbeitsverzeichnis:
$ initial_setup
HEAD: 2
Stage: 3
Worktree: 4
$ git checkout -- myfile
$ show_status
HEAD: 2
Stage: 3
Worktree: 3
git checkout HEAD -- myfile kopiert vom HEAD sowohl in den
Index, als auch ins Arbeitsverzeichnis:
$ initial_setup
HEAD: 2
Stage: 3
Worktree: 4
$ git checkout HEAD -- myfile
$ show_status
HEAD: 2
Stage: 2
Worktree: 2
git commit myfile kopiert vom Arbeitsverzeichnis in den Index
und zum HEAD:
$ initial_setup
HEAD: 2
Stage: 3
Worktree: 4
$ git commit myfile -m "version 4"
[main 679ff51] version 4
1 file changed, 1 insertion(+), 1 deletion(-)
$ show_status
HEAD: 4
Stage: 4
Worktree: 4
Copyright © 2010, Mark Lodato. German translation © 2012 Martin Funk, © 2017 Mirko Westermeier.
 Dieses Werk ist lizensiert unter Creative
Commons Namensnennung - Nicht-kommerziell - Weitergabe unter gleichen Bedingungen 3.0 Deutschland.
Dieses Werk ist lizensiert unter Creative
Commons Namensnennung - Nicht-kommerziell - Weitergabe unter gleichen Bedingungen 3.0 Deutschland.