Se as figuras não funcionarem, você pode tentar a versão sem SVG desta página.
As figuras SVG foram desabilitadas. (Reabilitar as figuras SVG)
Esta página fornece uma breve referência visual para os comandos mais comuns do git. Uma vez que você saiba um pouco sobre como o git funciona, esta página pode consolidar o seu entendimento. Se você está interessado em saber como esta página foi criada, veja o meu repositório no GitHub.
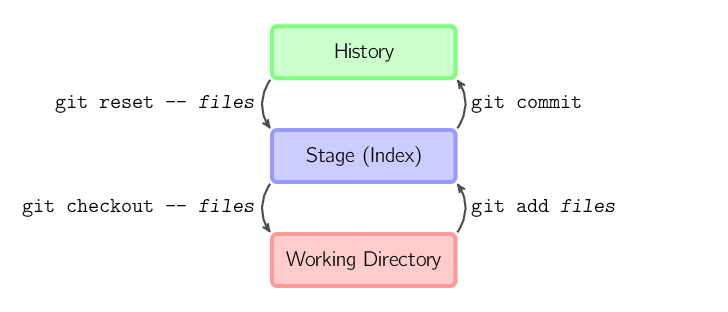
Os quatro comandos acima copiam arquivos entre o diretório de trabalho, o stage (também chamado de índice), e o histórico (na forma de commits).
git add arquivos copia arquivos (em
seus estados atuais) para o stage.git commit salva uma cópia do stage como um
commit.git reset -- arquivos remove arquivos do
stage; isto é, copia arquivos do último commit para o stage.
Use esse comando para "desfazer" um git add
arquivos. Você também pode executar git
reset para remover todos os arquivos do stage.git checkout -- arquivos copia
arquivos do stage para o diretório de trabalho. Use isso
para descartar alterações locais.Você pode usar git reset -p, git checkout
-p, ou git add -p em vez de (ou além de) especificar
arquivos para selecionar interativamente partes de arquivos para
copiar.
Também é possível passar por cima do stage e copiar (checkout) arquivos diretamente do histórico ou de commits sem copiar o aquivo para o stage.
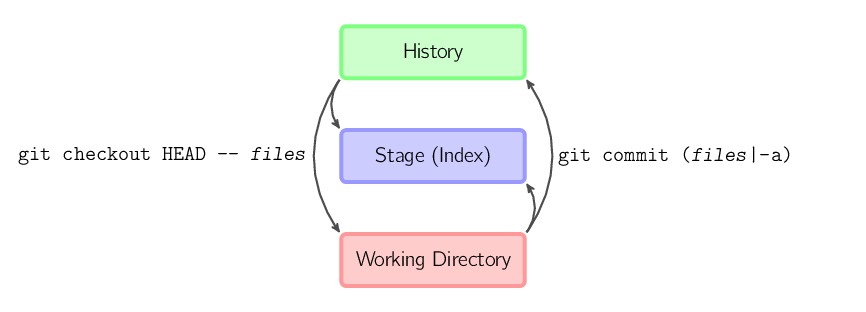
git commit -a é equivalente a executar git
add em todos os arquivos que existiam no último commit, e
então executar git commit.git commit arquivos cria um novo commit com
o conteúdo do último commit, mais uma cópia de arquivos no
diretório de trabalho. Além disso, os arquivos são copiados
para o stage.git checkout HEAD -- arquivos copia os
arquivos do último commit para ambos o stage e o diretório de
trabalho.No restante deste documento, nós vamos usar gráficos no seguinte formato.
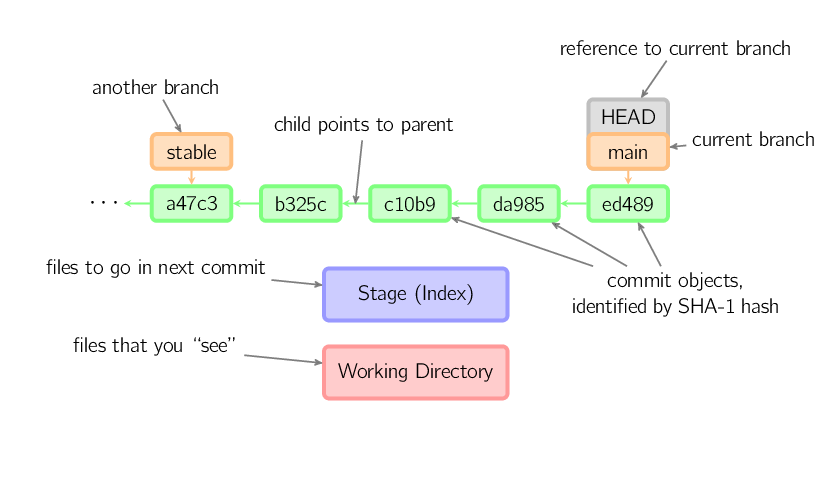
commits são mostrados em verde com uma identidade de 5 caracteres, e eles apontam para os seus pais (parents). Os ramos (branches) são mostrados em laranja, e eles apontam para commits específicos. O ramo atual é identificado pela referência especial HEAD, que está unida àquele ramo. Nessa imagem, os últimos cinco commits são mostrados, sendo ed489 o mais recente. main (o ramo atual) aponta para esse commit, enquanto stable (outro ramo) aponta para um ancestral do commit do main.
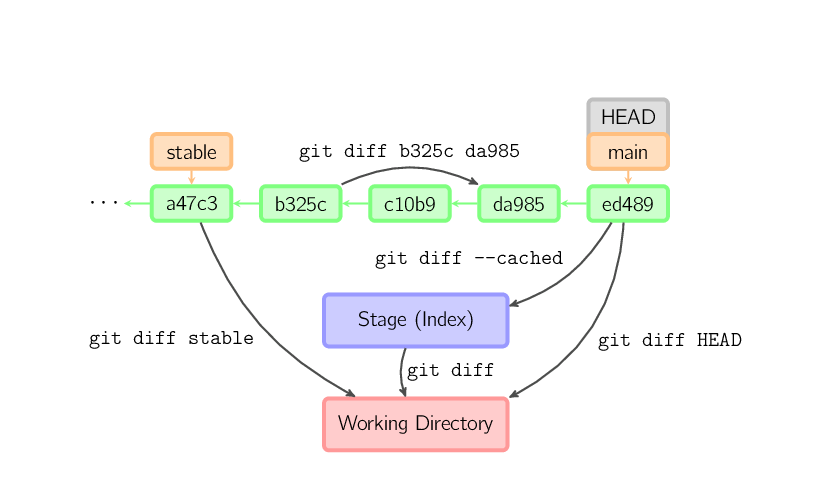
Existem várias formas de ver as diferenças entre commits. Abaixo estão alguns exemplos comuns. Qualquer desses comandos pode opcionalmente receber nomes de arquivos como argumentos que restringem as diferenças a esses arquivos.
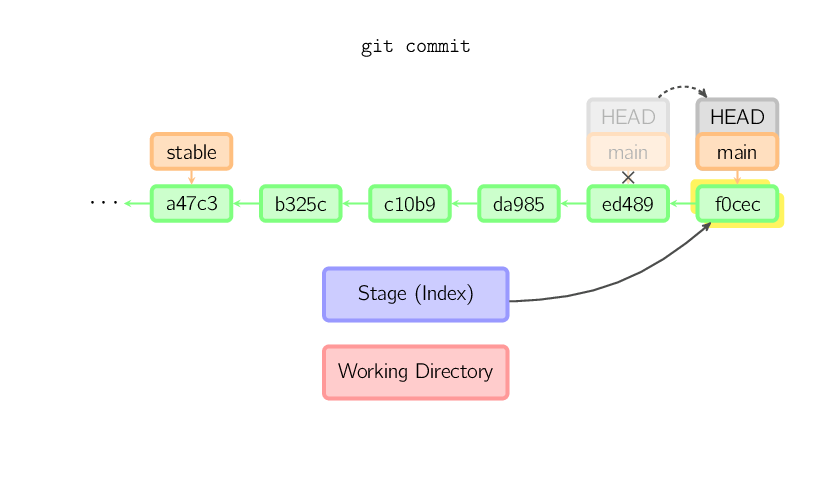
Quando você comita, o git cria um novo commit usando os arquivos do stage e define os pais como o commit atual. Então ele aponta o ramo atual para esse novo commit. Na figura abaixo, o ramo atual é o main. Antes do comando ser executado, main apontava para ed489. Após, um novo commit, f0cec, foi criado, com ancestral ed489, e então main foi movido para o novo commit.
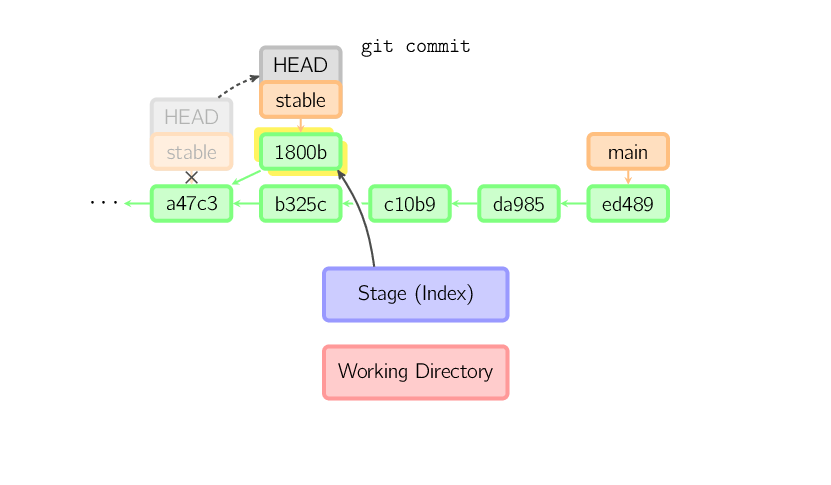
Esse mesmo processo ocorre também quando o ramo atual é um ancestral de outro ramo. Abaixo, um commit ocorre no ramo stable, o qual era um ancestral de main, resultando em 1800b. Após, stable não é mais um ancestral de main. Para juntar as duas histórias, um merge (ou rebase) será necessário.
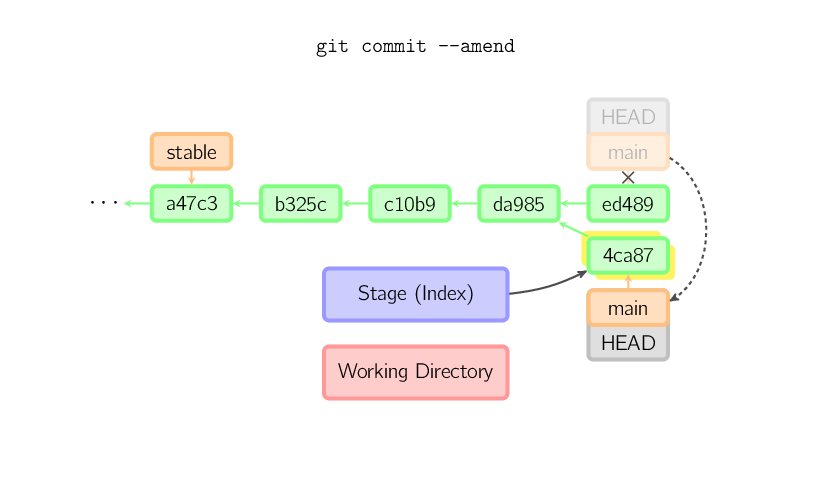
As vezes um engano ocorre em um commit, mas isso é fácil de corrigir
com git commit --amend. Quando você usa esse comando, o git
cria um novo commit com os mesmos pais do commit atual. (O commit antigo
será descartado se nada fizer referência a ele.)
Um quarto caso é comitar com o HEAD detachado, como explicado mais tarde.
O comando checkout é usado para copiar arquivos do histórico, ou stage, para o diretório de trabalho, e opcionalmente mudar de ramo.
Quando um nome de arquivo (e/ou -p) é fornecido, o git
copia esse arquivo do commit para o stage e para o diretório de trabalho.
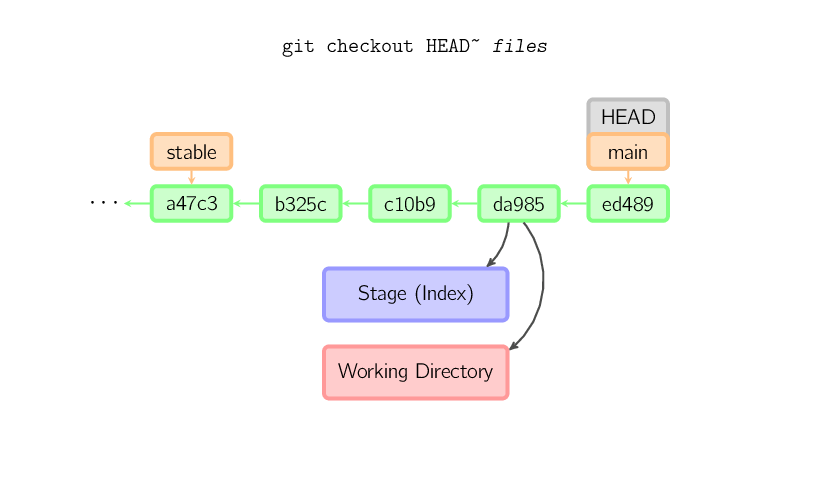
Por exemplo, git checkout HEAD~ foo.c copia o arquivo
foo.c do commit chamado HEAD~ (os pais do commit
atual) para o diretório de trabalho, e também para o stage. (Se nenhum
commit é fornecido, os arquivos são copiados do stage.) Note que não há
mudança no ramo.
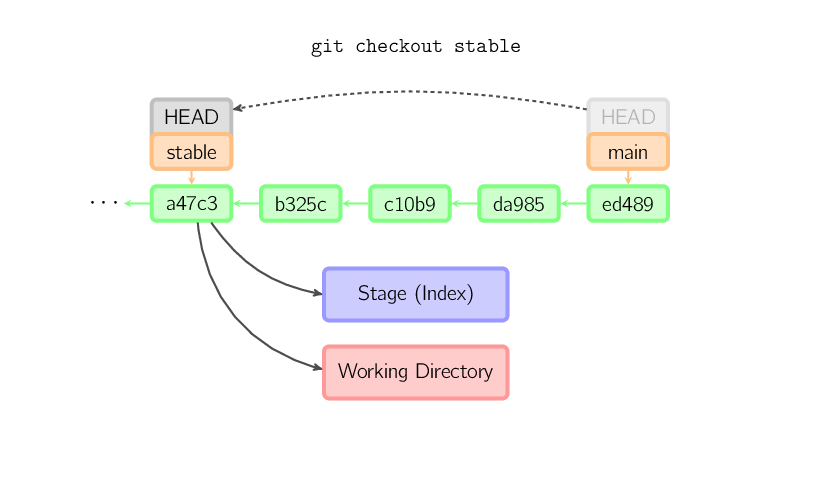
Quando um nome de arquivo não é fornecido mas a referência é um ramo (local), HEAD é movido para aquele ramo (isto é, nós passamos para aquele ramo), e então o stage e o diretório de trabalho são modificados para coincidir com o conteúdo daquele commit. Qualquer arquivo que existe no novo commit (a47c3 abaixo) é copiado; qualquer arquivo que existe no antigo commit (ed489) mas não no novo commit é excluído; e qualquer arquivo que não existe em ambos é ignorado.
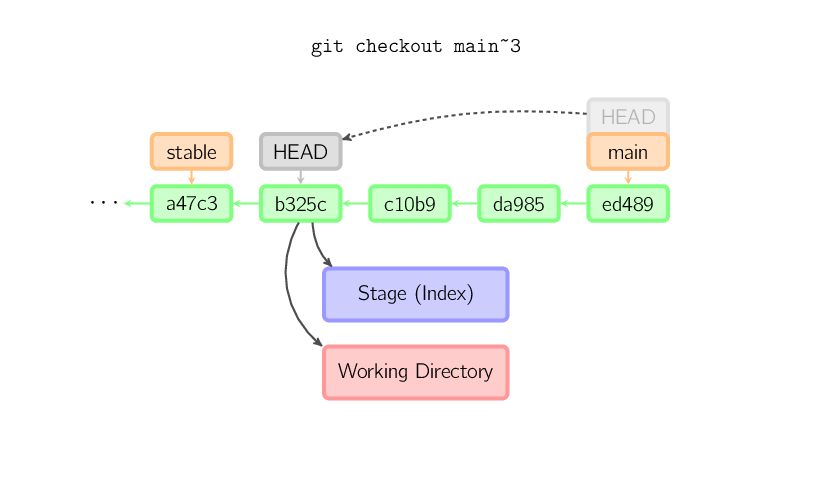
Quando um nome de arquivo não é fornecido e a referência
não é um ramo (local) — por exemplo, é uma etiqueta
(tag), um ramo remoto, uma identidade SHA-1, ou algo como
main~3 — nós obtemos um ramo anônimo, chamado HEAD
detachado. Isso é útil para se mover ao longo do histórico. Por
exemplo, suponha que você queira compilar a versão 1.6.6.1 do git. Você
poder executar git checkout v1.6.6.1 (que é uma etiqueta,
não um ramo), compilar, instalar, e então passar de volta para outro
ramo, por exemplo executado git checkout main. Todavia,
efetuar um commit funciona um pouco diferente em um HEAD detachado; isso
é discutido abaixo.
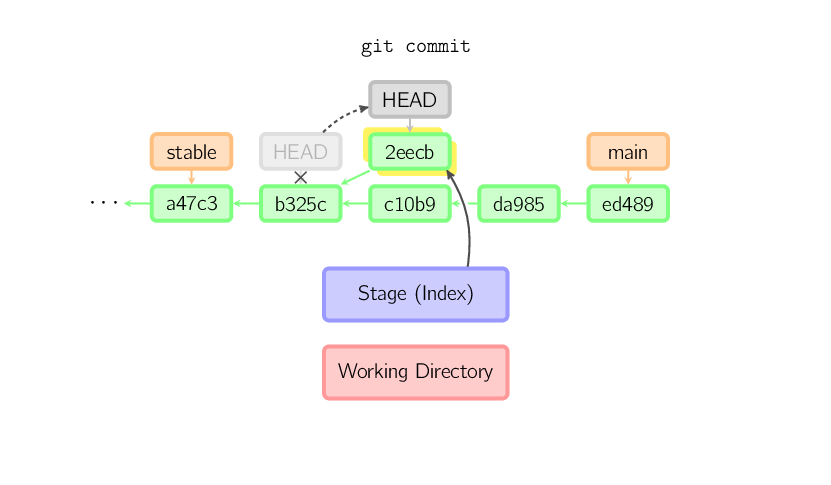
Quando o HEAD está detachado, comitar funciona da maneira usual, exceto que nenhum ramo com nome é modificado. (Você pode pensar nisso como um ramo anônimo.)
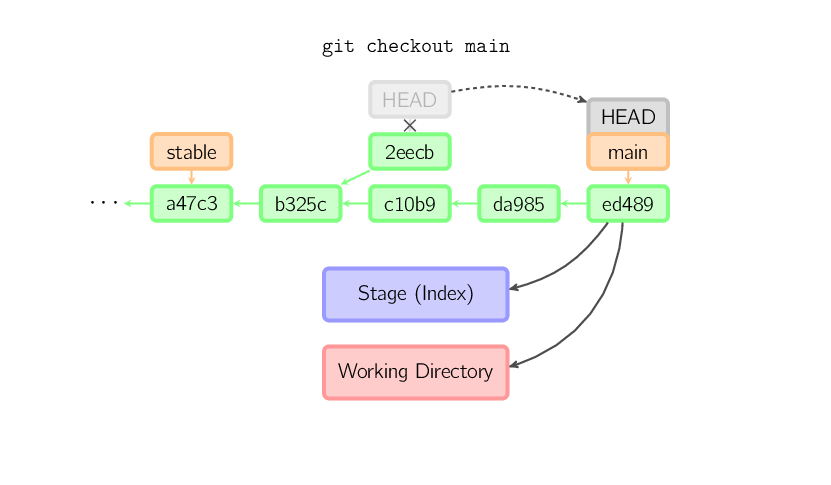
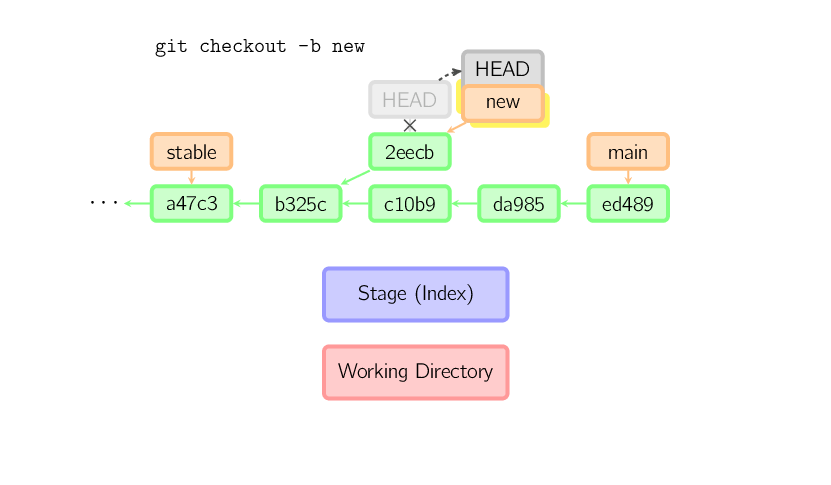
Uma vez que você fizer um checkout de alguma coisa, por exemplo main, o commit (presumivelmente) não recebe outra referência, e acaba excluído. Note que após o comando, não há nada fazendo referência para 2eecb.
Se, por outro lado, você quiser salvar esse estado, você pode criar
um novo ramo com nome usando git checkout -b
nome.
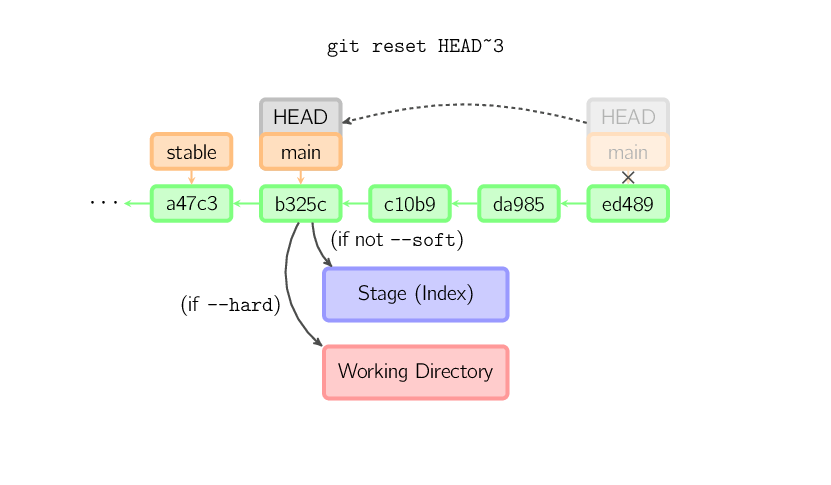
O comando reset move o ramo atual para uma nova posição, e opcionalmente atualiza o stage e o diretório de trabalho. Ele também é usado para copiar arquivos do histórico para o stage sem alterar o diretório de trabalho.
Se um commit é realizado sem um nome de arquivo, o ramo atual é
movido para aquele commit, e então o stage é atualizado para coincidir
com esse commit. Se --hard é fornecido, o diretório de
trabalho também é atualizado. Se --soft é fornecido,
nem o stage nem o diretório de trabalho são atualizados.
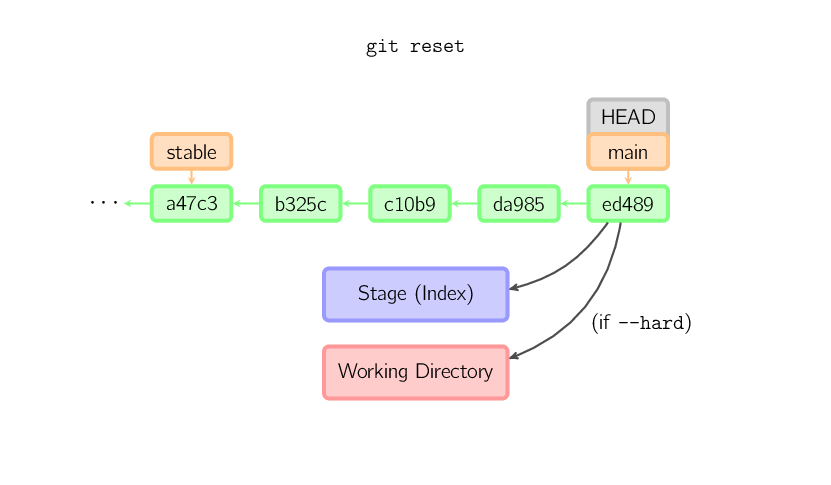
Se um commit não é fornecido, será usado o HEAD. Nesse
caso, o ramo não é alterado, mas o stage, e opcionalmente o diretório de
trabalho se --hard é fornecido, são atualizados com o
conteúdo do último commit.
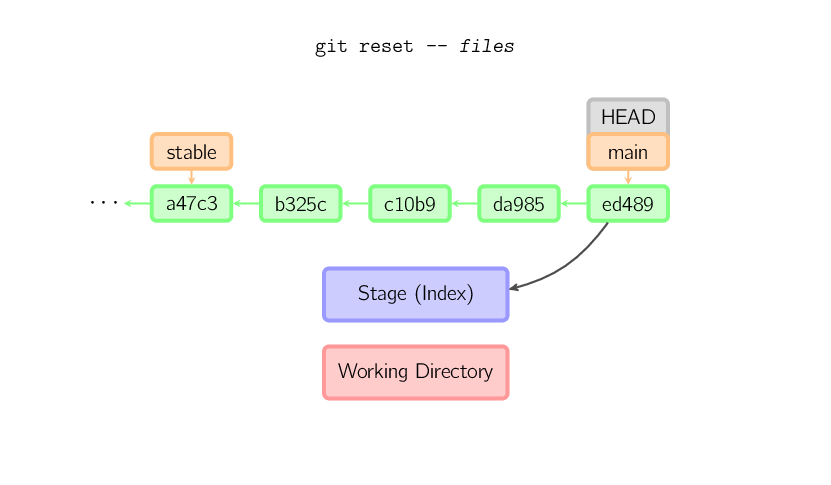
Se um nome de arquivo (e/ou -p) é fornecido, então o
comando funciona similarmente ao comando checkout com um nome de arquivo, exceto que
apenas o stage (e não o diretório de trabalho) é atualizado. (Você pode
também especificar o commit a partir do qual copiar os arquivos, em vez
de HEAD.)
Um merge cria um novo commit que incorpora mudanças de outros commits. Antes de executar um merge, o stage deve estar igual ao último commit. O caso trivial é quando o outro commit é um ancestral do commit atual; em tal caso nada ocorre. O próximo caso mais simples é quando o commit atual é um ancestral do outro commit. Isso resulta em um merge fast-forward. A referência é simplesmente movida, e então é efetuado um checkout do novo commit.
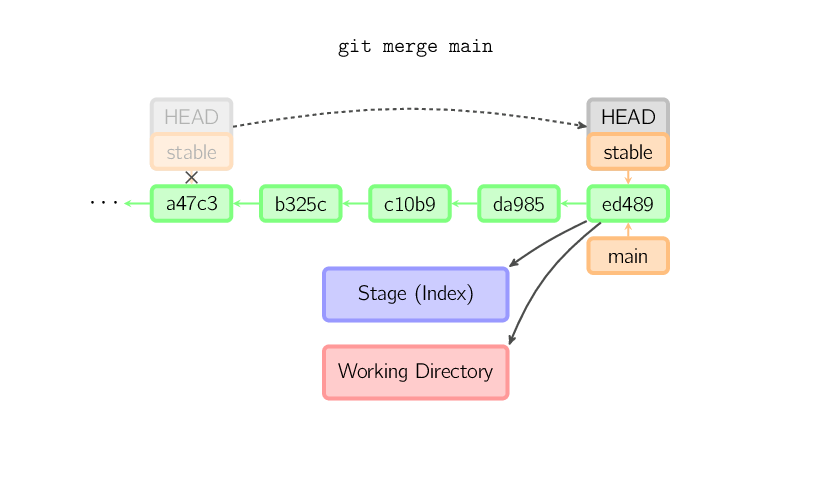
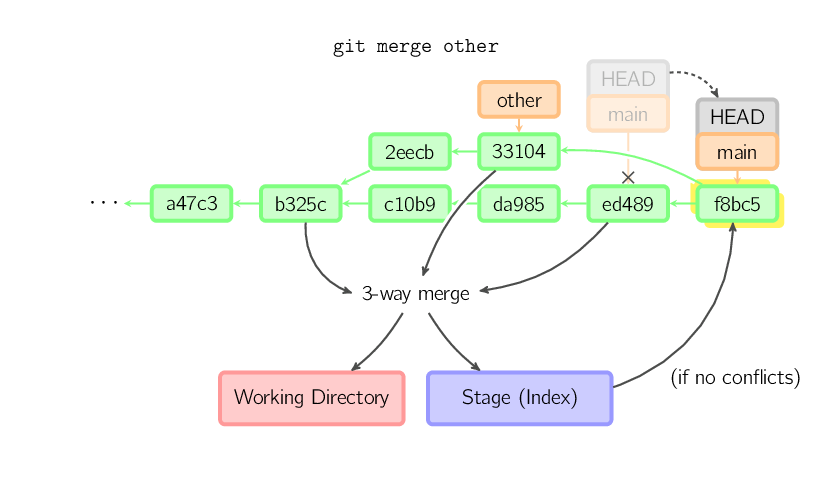
Caso contrário, um merge "real" deve ocorrer. Você pode selecionar outras estratégias, mas o padrão é efetuar um merge "recursivo", o qual basicamente considera o commit atual (ed489 abaixo), o outro commit (33104), e o ancestral comum a ambos (b325c), e efetua um merge three-way. O resultado é salvo no diretório de trabalho e no stage, e então um commit é executado, com um ancestral adicional (33104) para o novo commit.
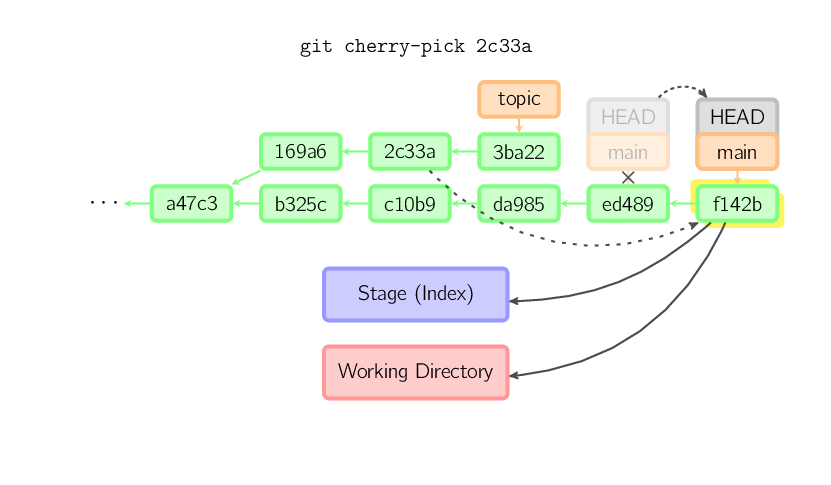
O comando cherry-pick "copia" um commit, criando um novo commit no ramo atual com a mesma mensagem e modificações de outro commit.
Um rebase é uma alternativa a um merge para combinar vários ramos. Enquanto um merge cria um único commit com dois pais, gerando um histórico não-linear, um rebase efetua os commits do ramo atual em outro ramo, gerando um histórico linear. Em essência, isso é uma forma automática de executar vários cherry-picks em sequência.
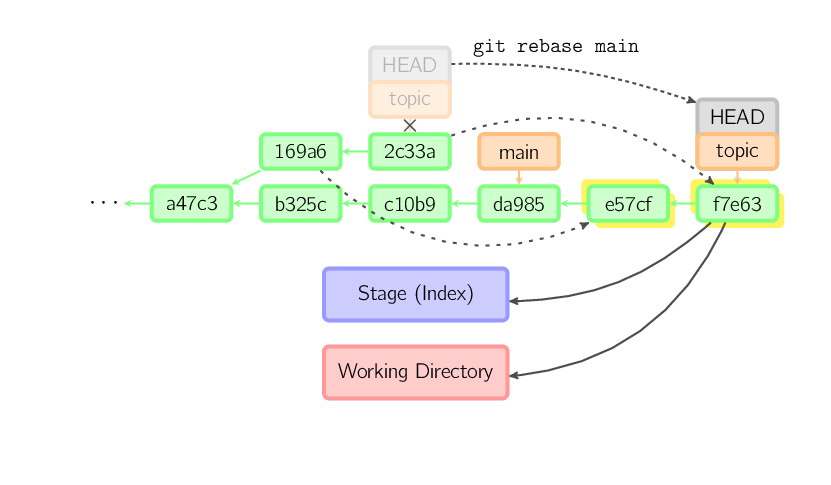
O comando acima considera todos os commits que existem em topic mas não em main (a saber 169a6 e 2c33a), executa esses commits em main, e então move o HEAD para o novo commit. Note que os commits antigos serão descartados se nada mais fizer referência a eles.
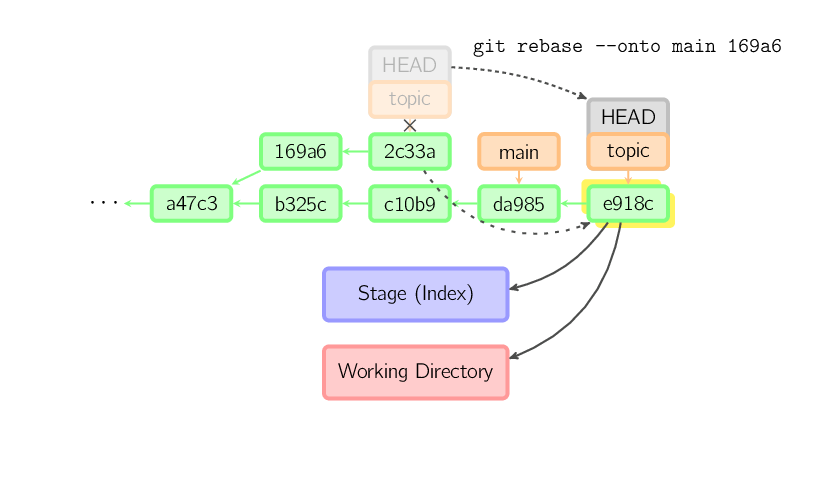
Para limitar quanto se quer ir para trás, use a opção
--onto. O seguinte comando executa em main os
commits mais recentes do ramo atual desde 169a6
(exclusivamente), a saber 2c33a.
Existe também o comando git rebase --interactive, o qual
permite fazer coisas mais complicadas do que simplesmente executar
novamente commits, a saber, remover, reordenar, modificar, e "amassar"
commits (squashing). Não existe uma figura clara para representar isso;
veja git-rebase(1)
para mais detalhes.
O conteúdo dos arquivos não é na verdade armazenado no index (.git/index) ou em objetos commit. Em vez disso, cada arquivo é armazenado na base-de-dados de objetos (.git/objects) como um blob, identificado pelo seu código hash SHA-1. O arquivo index lista os nomes de arquivos juntamente com o identificador do blob associado, bem como alguns outros dados. Para commits, existe um tipo de dado adicional, uma árvore, também identificado pelo seu código hash. Árvores correspondem aos diretórios no diretório de trabalho, e contém uma lista das árvores e blobs correspondentes a cada nome de arquivo naquele diretório. Cada commit armazena o identificador da sua árvore, que por sua vez contém todos os blobs e outras árvores associadas àquele commit.
Se você realiza um commit usando um HEAD detachado, o último commit é
na verdade referenciado por algo: o reflog para o HEAD. Todavia, esse
possui data de validade, logo em algum momento posterior o commit
será finalmente excluído, de forma similar aos commits excluídos com
git commit --amend ou git rebase.
Copyright © 2010, Mark Lodato. Portuguese translation © 2014, Gustavo de Oliveira
 Este trabalho está sob a licença
Atribuição-NãoComercial-CompartilhaIgual 3.0 Estados Unidos.
Este trabalho está sob a licença
Atribuição-NãoComercial-CompartilhaIgual 3.0 Estados Unidos.