Si les images ne s'affichent pas, vous pouvez utiliser la version Non-SVG de cette page.
Les images SVG ont été désactivées. (Réactiver SVG)
Cette page donne une brève référence visuelle des principales commandes git. Une fois que vous connaissez un peu comment fonctionne git, cette page vous permettra d'asseoir votre compréhension. Si vous voulez savoir comment ce site a été créé, allez voir mon dépôt GitHub.
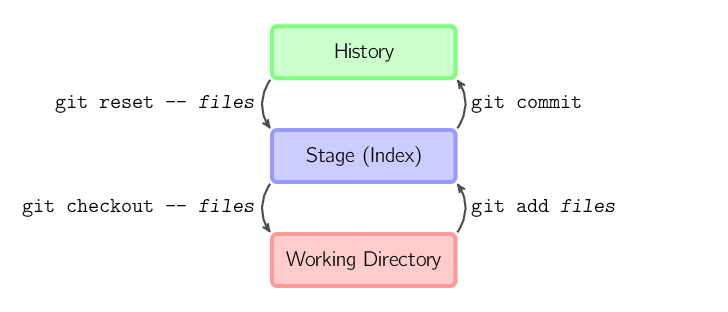
Les quatre commandes ci-dessus copient des fichiers entre la working copy (copie de travail), le stage (aussi appelé l'index), et l'histoire (sous la forme de commits).
git add fichiers copie les fichiers (dans leur
état courant) vers le stage.git commit fait un "cliché" du stage sous la forme d'un
commit.git reset -- fichiers supprime les fichiers du stage ; i.e. elle
copie les fichiers du dernier commit vers le stage. Utilisez cette
commande pour annuler une commande git add fichiers. Vous pouvez aussi faire un
git reset pour vider complètement le stage.git checkout -- fichiers copie les fichiers du
stage vers la working copy (copie de travail). Utilisez cette commande pour annuler
des changements locaux (ceux de votre copie de travail).Vous pouvez utiliser git reset -p, git checkout -p, ou
git add -p au lieu de (ou en plus de) spécifier des fichiers particuliers
pour choisir interactivement quels morceaux doivent être copiés.
Il est également possible de contourner complètement le stage et de sortir (check out) les fichiers directement de l'histoire, ou de commiter les fichiers sans les faire passer préalablement par le stage.
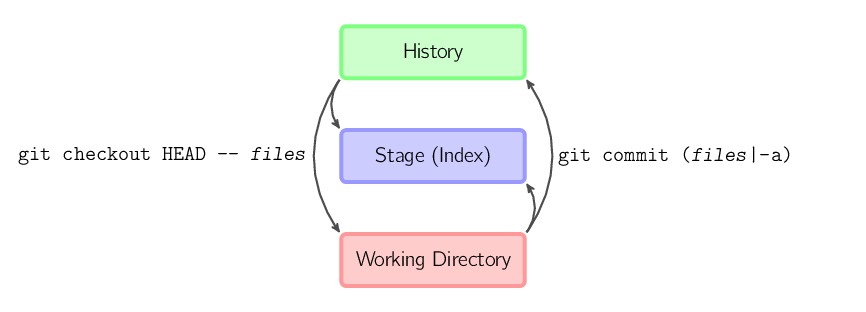
git commit -a revient à exécuter successivement git add
sur tous les fichiers qui existaient dans le dernier commit, puis
git commit.git commit fichiers crée un nouveau commit
incluant le contenu du dernier commit, plus un cliché des fichiers pris
dans la working copy. De plus, les fichiers sont copiés dans
le stage.git checkout HEAD -- fichiers copie les fichiers
depuis le dernier commit vers à la fois le stage et la working copy.Dans la suite de ce document, nous allons utiliser des graphiques de la forme suivante.
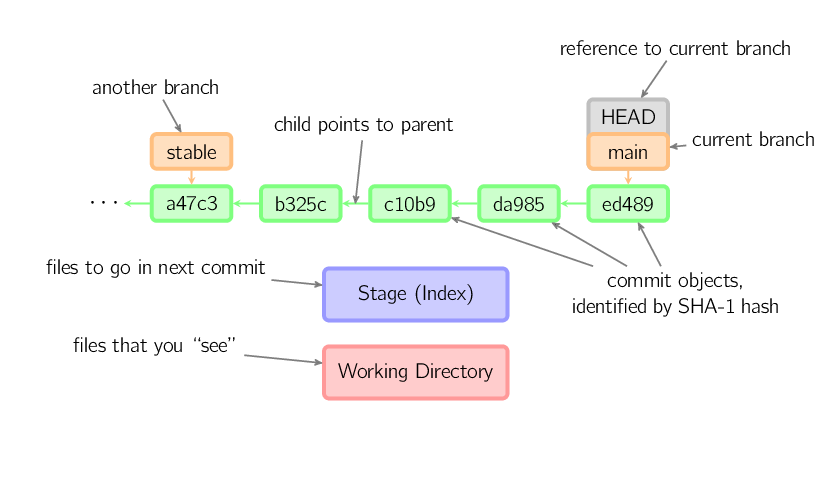
Les commits sont représentés en vert, avec des IDs à 5 caractères et ils pointent vers leurs parents. Les branches sont représentées en orange, et elles pointent vers des commits particuliers. La branche courante est idendifiée par la référence HEAD, qui est "attachée" à cette branche. Dans cette image les cinq derniers commits sont représentés, ed489 étant le plus récent. main (la branche courante) pointe vers ce commit, alors que stable (une autre branche) pointe vers un ancêtre du commit main.
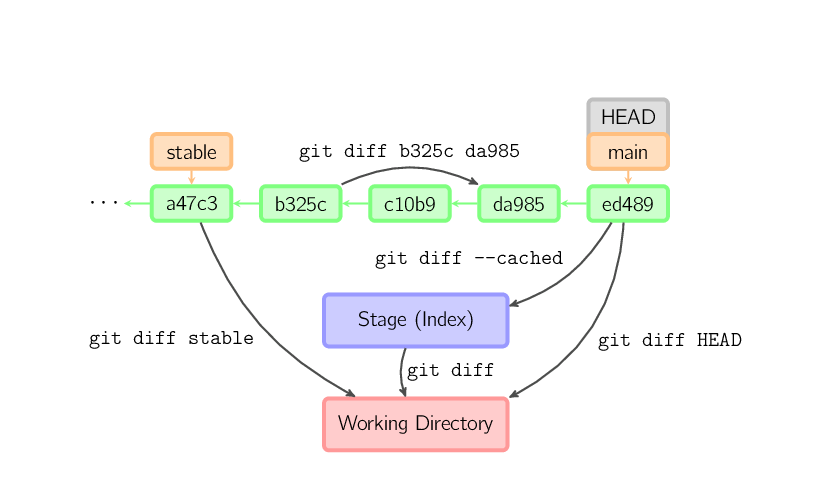
Il y a plusieurs façons de visualiser les différences entre commits. Vous trouverez ci-dessous quelques exemples courants. Toutes ces commandes peuvent également prendre des noms de fichers comme arguments supplémentaires. Ils restreignent alors les différences affichées aux fichiers désignés.
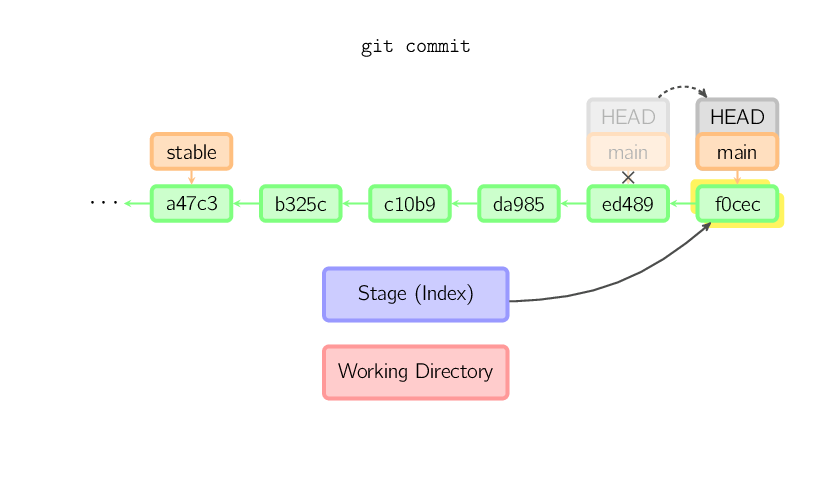
Quand vous commitez, git crée un nouvel objet de type "commit" en utilisant les fichiers présents dans le stage, et en prenant comme parent le commit courant. Il déplace aussi la branche courante vers ce nouveau commit. Sur l'image ci-dessous, la branche courante est main. Avant que la commande ne soit exécutée, main pointait sur ed489. Après l'exécution de la commande, un nouveau commit f0cec est créé, avec ed489 comme parent, et main est déplacé pour pointer sur ce nouveau commit.
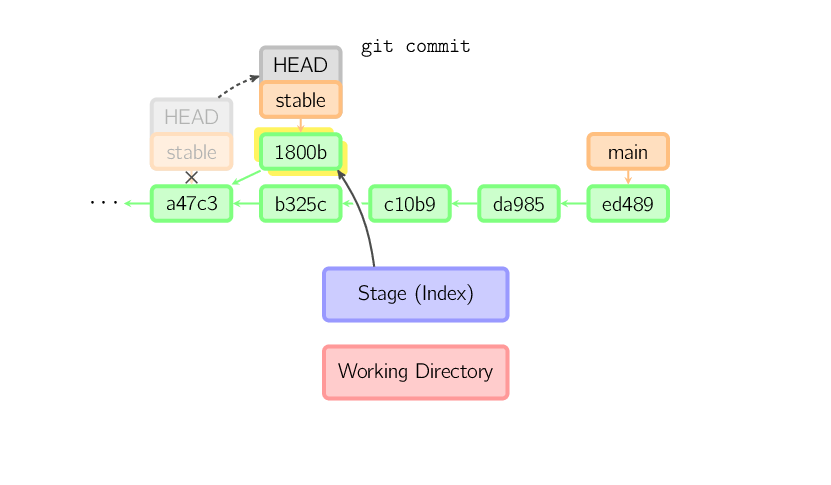
Ce fonctionnement est systématique, même si la branche courante est un ancêtre d'une autre. Ci-dessous, un commit a lieu sur une branche stable, qui est un ancêtre de main. Le commit résultant est : 1800b ; stable n'est alors plus un ancêtre de main. Pour consolider ces deux histoires (maintenant divergentes), un merge (ou un rebase) va être nécessaire.
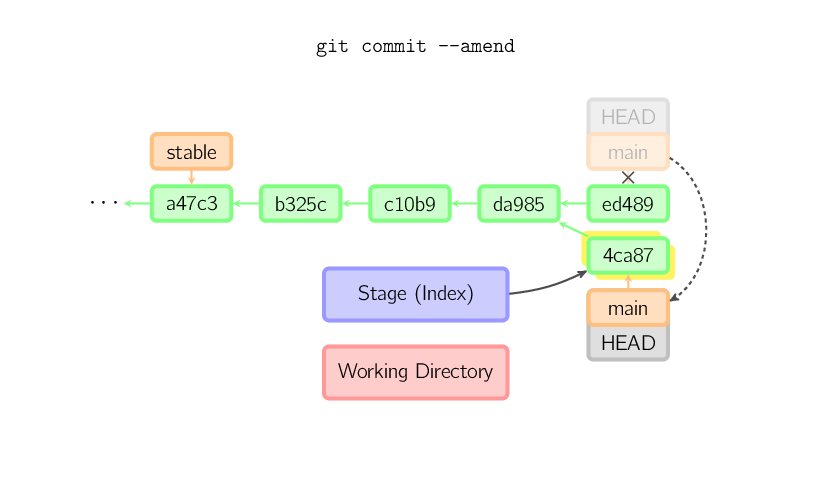
Si vous commettez une erreur dans un commit, il est facile de la corriger avec
git commit --amend. Quand vous utilisez cette commande, git crée un
nouveau commit avec le même parent que le commit courant. (L'ancien commit sera supprimé
s'il n'y a plus aucun élément — une branche par exemple — qui le référence).
Une quatrième situation un peu particulière consiste à commiter avec une detached HEAD (HEAD détachée), comme expliqué ci-après.
La commande checkout est utilisée pour copier des fichiers de l'histoire (ou du stage) vers la working copy, mais également pour passer d'une branche à une autre.
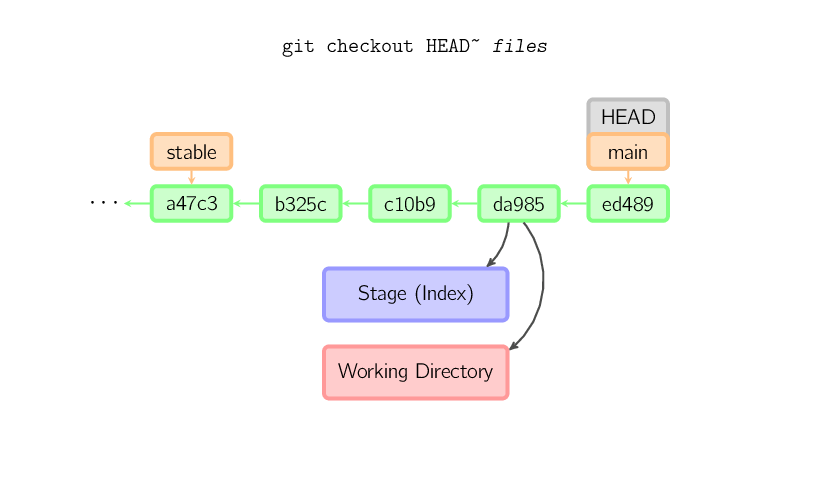
Quand un nom de fichier (ou -p) est passé en paramètre, git copie ces fichiers
depuis le commit concerné vers le stage et vers la working copy. Par exemple,
git checkout HEAD~ foo.c copie le fichier foo.c
depuis le commit nommé HEAD~ (le parent du commit courant) vers
la working copy, et le place aussi dans le stage. (Si aucun nom de commit n'est donné,
les fichiers sont copiés depuis le stage). Notez que la branche courante n'est pas modifiée.
Quand aucun nom de fichier n'est passé en argument, et que la référence est une branche (locale), HEAD est déplacée vers cette branche (i.e. on "bascule" sur cette branche), et le stage ainsi que la working copy s'ajustent pour correspondre au contenu de ce commit. Les fichiers qui existent dans le nouveau commit (a47c3 ci-dessous) sont copiés ; les fichiers qui existent dans l'ancien commit (ed489) mais pas dans le nouveau sont supprimés ; et les fichiers qui n'existent dans aucun des deux sont ignorés.
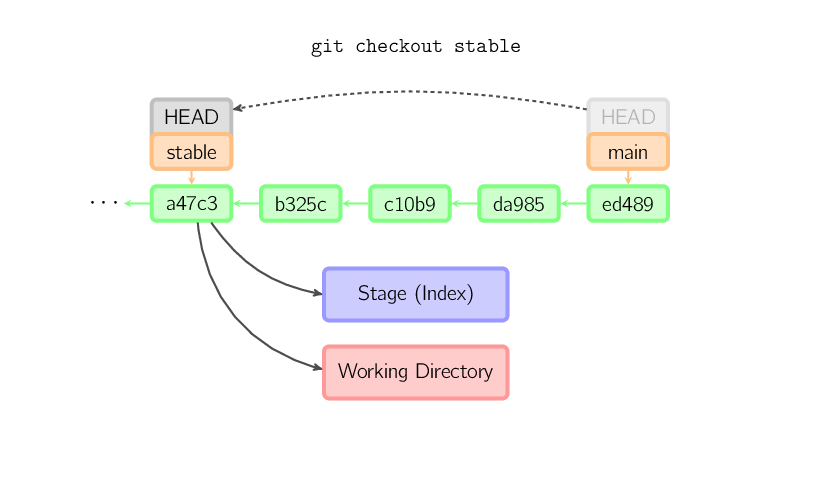
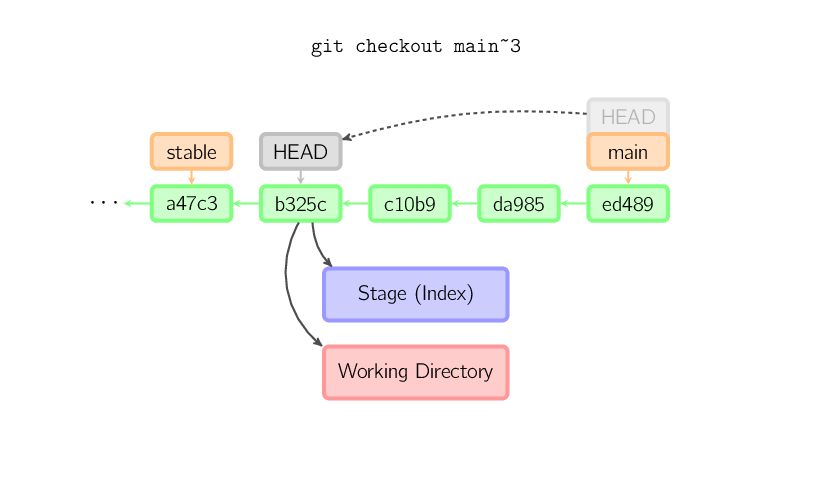
Quand aucun nom de fichier n'est donné et que la référence n'est pas une
banche (locale) — i.e. c'est un tag, une branche distante, un ID SHA-1 ou un truc du genre
main~3 — on se retrouve avec une branche anonyme appelée
une detached HEAD. Ceci est utile pour se déplacer rapidement dans l'histoire.
Supposons que vous souhaitiez compiler la version 1.6.6.1 de git. Vous pouvez faire un
git checkout v1.6.6.1 (qui est un tag, et non une branche), compiler, installer,
et rebasculer sur une autre branche, avec par exemple git checkout main.
Cela dit, commiter fonctionne légèrement différemment avec une "detached HEAD" ;
voir les détails ci-dessous.
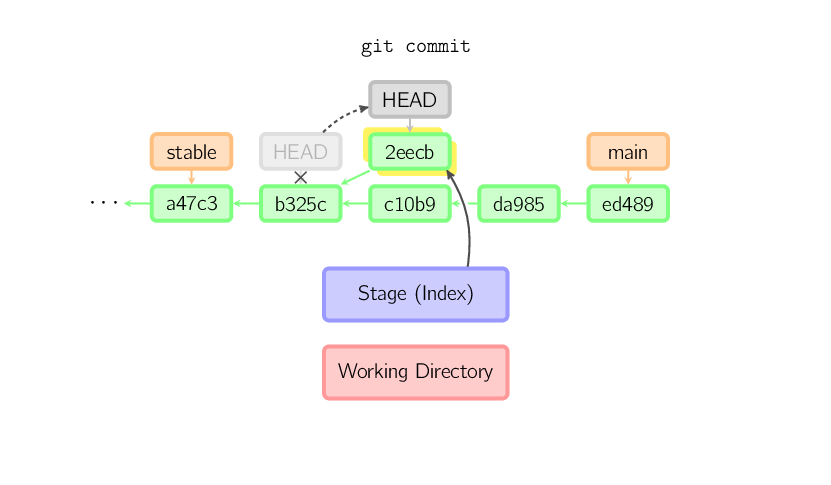
Quand votre HEAD est détachée, la commande commit fonctionne normalement, excepté le fait qu'aucune branche (nommée) n'est mise à jour. (Vous pouvez voir ça comme une branche anonyme).
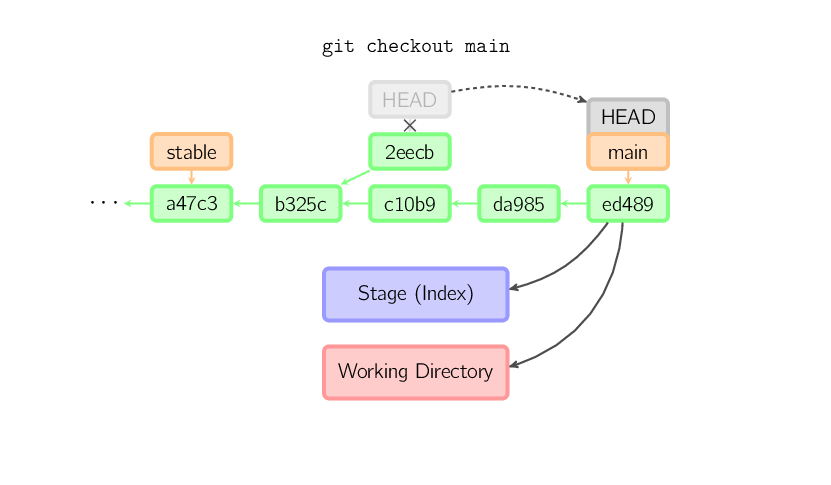
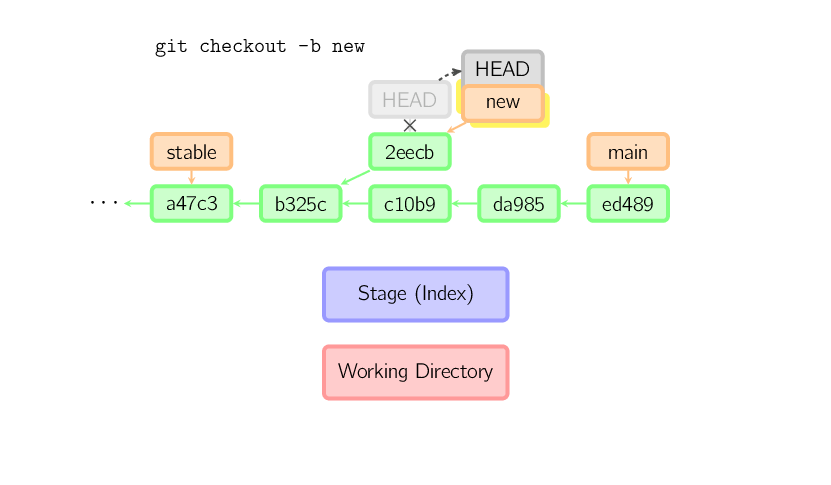
Une fois que vous basculez sur une autre branche, par exemple main, le commit n'est (possiblement) plus référencé par aucun élément (branche, tag, ...), et est perdu. Notez qu'après la commande, le commit 2eecb n'est plus référencé.
Si, au contraire, vous souhaitez conserver cet état, vous pouvez créer une nouvelle
branche (nommée), en utilisant git checkout -b nom_de_la_branche.
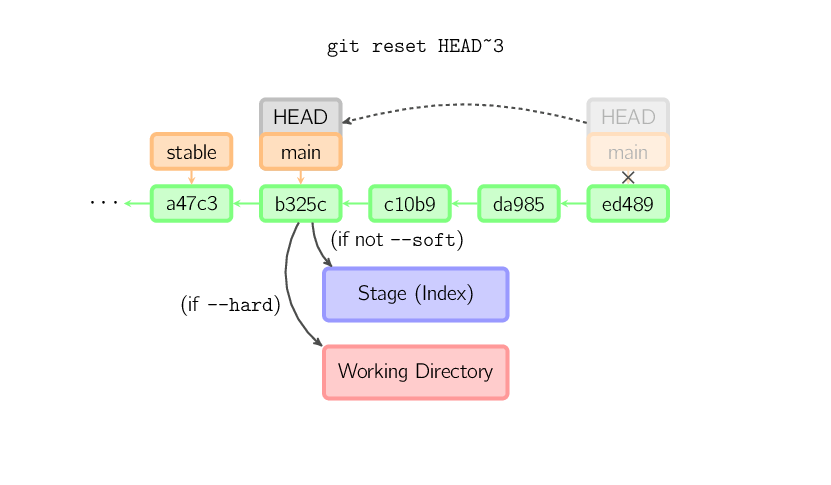
La commande reset déplace la branche courante à une autre position et met éventuellement à jour le stage et la working copy. Elle est également utilisée pour copier des fichiers depuis l'histoire vers le stage, sans toucher à la working copy.
Si un commit est passé en argument, sans nom de fichier, la branche courante est
déplacée vers ce commit, et le stage est mis à jour pour correspondre à ce commit.
Si l'option --hard est passée en argument, la working copy est aussi mise à jour.
Si l'option --soft est passée en argument, aucun des deux n'est mis à jour.
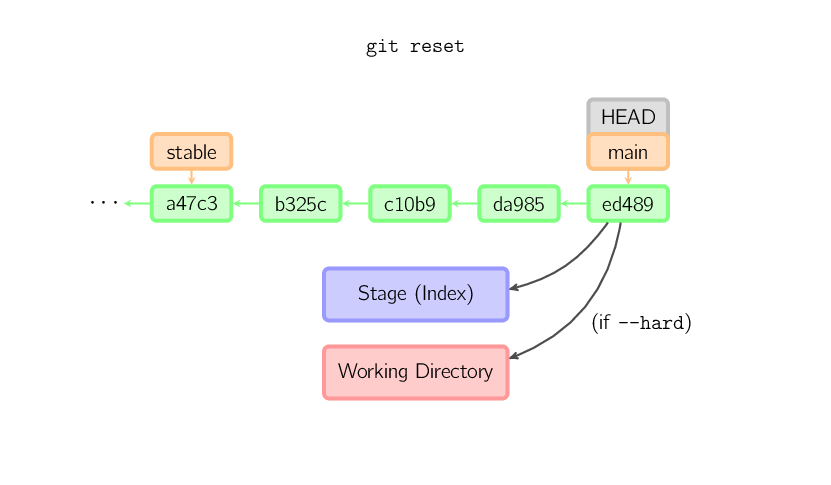
Si aucun commit n'est passé en argument, la valeur par défaut est HEAD.
Dans ce cas, la branche n'est pas déplacée, mais le stage (et éventuellement la working copy,
si l'option --hard est passée en argument) sont remis à zéro pour correspondre
au contenu du dernier commit.
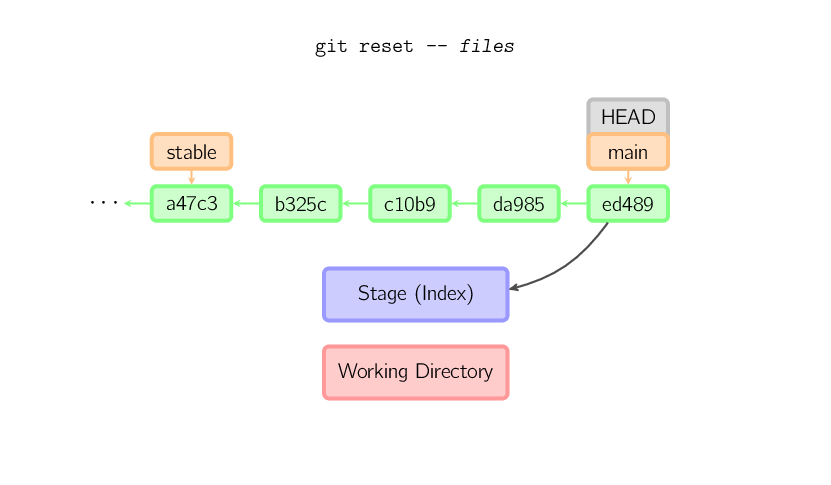
Si un fichier (et/ou l'option -p) est passé en argument, alors la commande
se comporte comme checkout avec un nom de fichier, hormis le fait
que seul le stage (et pas la working copy) est mis à jour. (Vous pouvez aussi spécifier
le commit à partir duquel prendre les fichiers, au lieu de HEAD.)
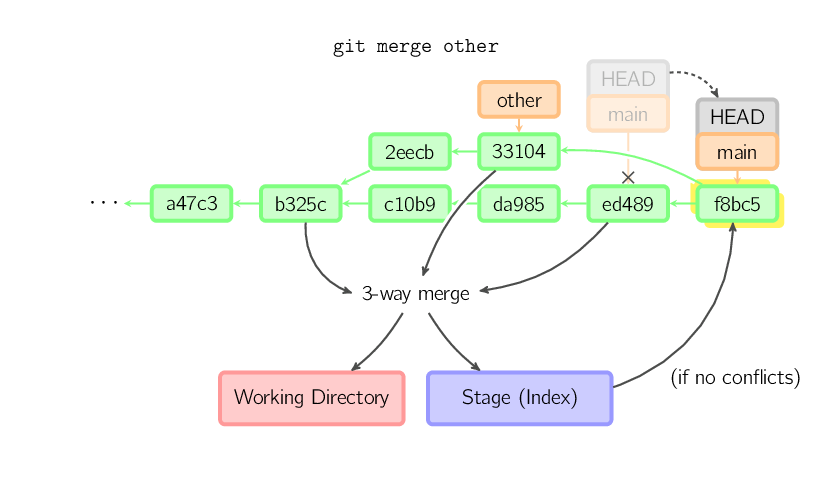
Un merge crée un nouveau commit qui incorpore les changements d'autres commits. Avant de merger, le stage doit correspondre au contenu du commit courant. Le cas trivial est si l'autre commit correspond à un ancêtre du commit courant. Dans ce cas, rien n'est fait. Un autre cas simple, est si le commit courant est un ancêtre de l'autre commit. L'opération résultante est nommée fast-forward (avance rapide) ; la référence est alors simplement déplacée, et le nouveau commit est "checked out".
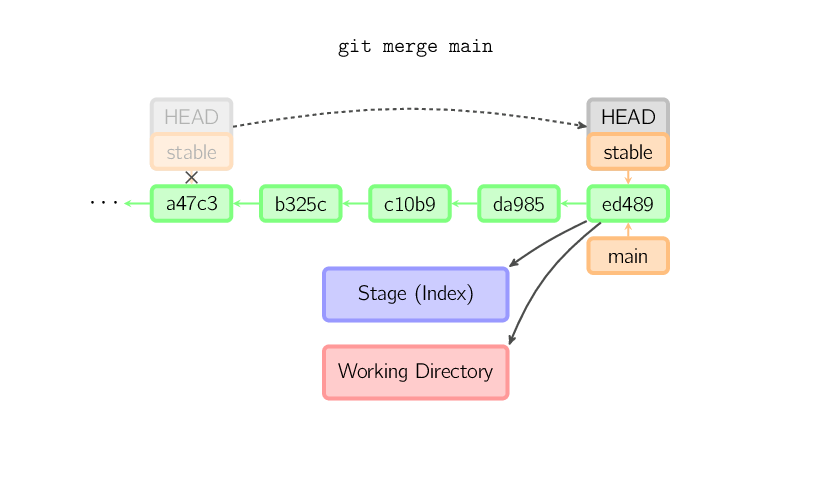
Dans les autres cas, un "vrai" merge est effectué. Vous pouvez choisir d'autres stratégies, mais par défaut c'est un merge "récursif" qui est effectué. Il consiste à prendre le commit courant (ed489 ci-dessous), et l'autre commit (33104), et leur ancêtre commun (b325c), et à effectuer un "three-way merge". Le résultat est placé dans la working copy et dans le stage, et un commit est effectué, avec un parent supplémentaire (33104).
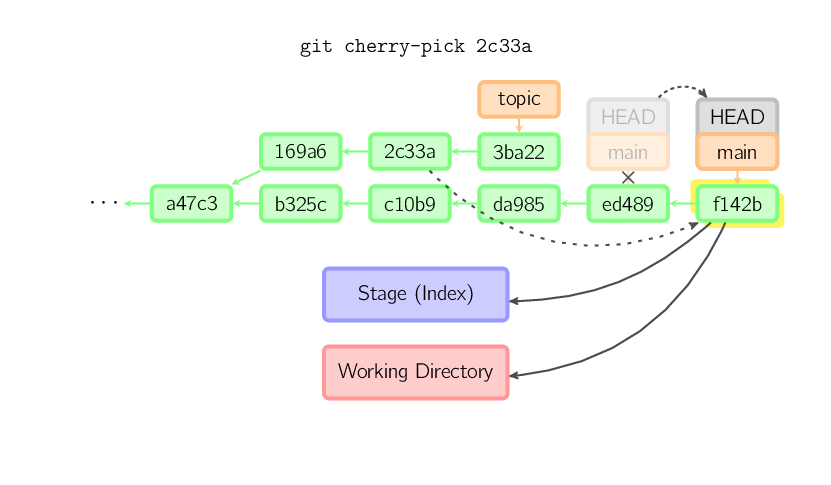
La commande cherry-pick copie un commit, en créant un nouveau commit sur la branche courante, avec le même message et le même "patch" que le commit désigné.
Un "rebase" est une alternative au merge pour combiner plusieurs branches. Alors q'un merge crée un commit unique avec deux parents, produisant une histoire non linéaire, un rebase rejoue les commits de la branche courante sur une autre branche, produisant une histoire linéaire. En fait, c'est une façon automatique d'effectuer plusieurs cherry-picks à la fois.
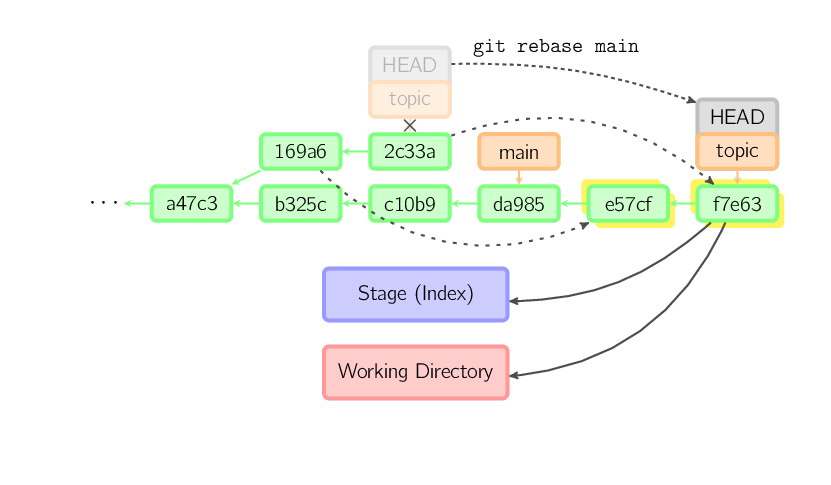
La commande ci-dessus prend tous les commits qui existent dans topic mais pas dans main (i.e. 169a6 et 2c33a), les rejoue sur main, puis déplace la branche (topic) en conséquence. Notez que les anciens commits seront supprimés (garbage collection) s'ils ne sont plus référencés.
Pour indiquer jusqu'où vous souhaitez remonter dans l'histoire, utilisez
l'otpion --onto.
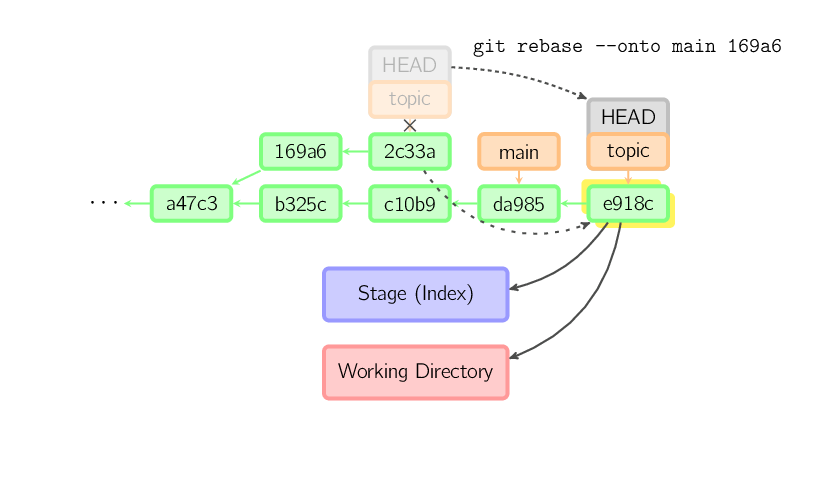
La command suivante rejoue sur main les commits les plus récents
de la branche courante depuis 169a6 (exclu), autrement dit
2c33a.
Il y aussi git rebase --interactive, qui permet d'effectuer
des opérations plus complexes, au delà de simplement rejouer des commits.
Comme par exemple supprimer des commits, réordonner des commits, modifier des commits,
ou rassembler plusieurs commit en un seul. Il n'y a pas de schéma évident pour ces opérations ; voir
git-rebase(1)
pour les détails.
Le contenu des fichiers n'est pas vraiment stocké dans l'index (.git/index) ou dans les commits. En réalité, chaque fichier est stocké dans la base de données d'objets (.git/objects) sous forme d'un blob, identifié par son hash SHA-1. Le fichier d'index liste les noms de fichier ainsi que l'identifiant du blob associé et quelques autres données. Pour les commits, il existe un autre type de donnée appelé tree, lui aussi identifié par son hash. Un "tree" correpond à un dossier dans la working copy, et contient une liste de "trees" et de "blobs" représentant respectivement ses sous-dossiers et ses sous-fichiers. Chaque commit stocke l'identifiant de son "tree" de plus haut niveau, qui lui-même contient tous les "blobs" et "trees" associés avec ce commit.
Si vous commitez avec une "detached HEAD", le dernier commit est en fait toujours
référencé par quelque chose : le "reflog" de HEAD. Néanmoins, il finira par
expirer, et le commit sera finalement perdu (garbage collection), de même que
les commits neutralisés par un git commit --amend ou un git
rebase.
Copyright © 2010, Mark Lodato. French translation © 2012, Michel Lefranc.
 Cette oeuvre est mise à disposition selon les termes de la Licence
Creative Commons Attribution - Pas d'Utilisation Commerciale - Partage
à l'Identique 3.0 États-Unis.
Cette oeuvre est mise à disposition selon les termes de la Licence
Creative Commons Attribution - Pas d'Utilisation Commerciale - Partage
à l'Identique 3.0 États-Unis.